
Como funcionam os modelos de linguagem generativa
Os modelos GPT têm sido notícia e muitas pessoas estão se perguntando como eles são implementados. Embora os detalhes de seu funcionamento interno sejam proprietários e complexos, suas ideias básicas são públicas e simples o suficiente para que todos possam entender.
O objetivo nesta postagem é explicar os fundamentos dos modelos generativos em geral e dos modelos GPT em particular, de uma forma que seja acessível ao público em geral. Se você é um especialista em IA, confira segue post equivalente para um público de AI.
Vamos começar explorando como funcionam os modelos de linguagem generativa. A ideia básica é a seguinte: eles levam tokens como entrada e produz um token como saída.
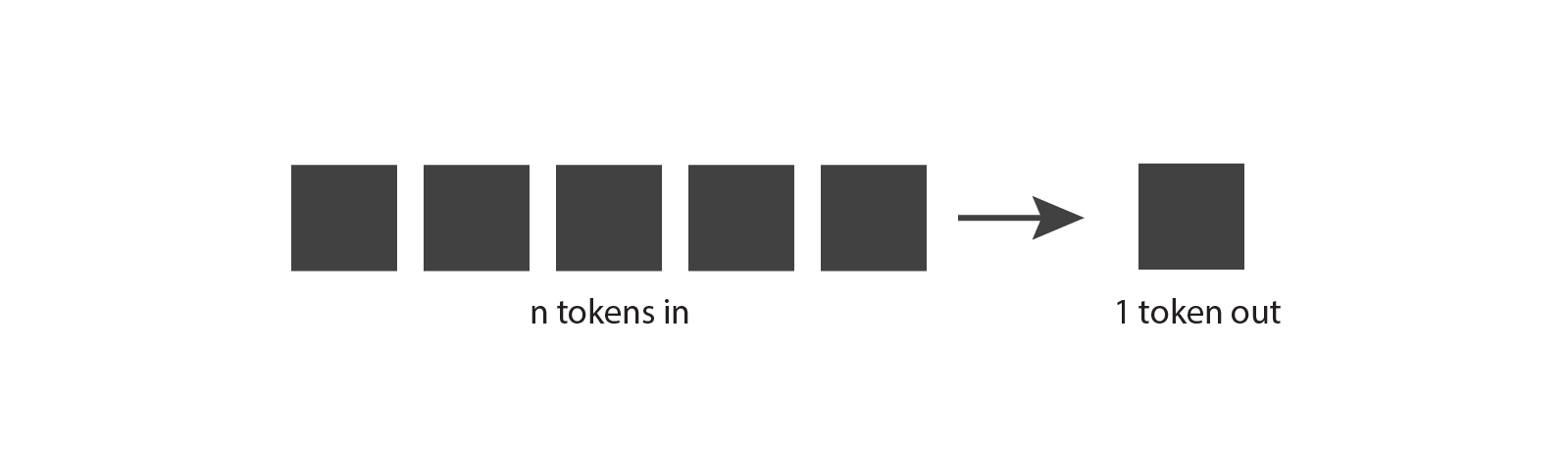
Este parece ser um conceito bastante simples, mas para realmente entendê-lo, precisamos saber o que é um token.
Um token é um pedaço de texto. No contexto dos modelos OpenAI GPT, palavras comuns e curtas normalmente correspondem a um único token, como a palavra “Nós” na imagem abaixo. Palavras longas e menos usadas são geralmente divididas em vários tokens. Por exemplo, a palavra “antropomorfização” na imagem abaixo é dividida em três tokens.
Abreviações como “ChatGPT” podem ser representadas por um único token ou divididas em vários, dependendo da frequência com que as letras apareçam juntas. Você pode ir para a página Tokenizer do OpenAI , inserir seu texto e ver como ele é dividido em tokens. Ou você pode usar a biblioteca tiktoken de código aberto para tokenizar usando código Python.

Isso lhe dá uma boa intuição de como funciona o tokenizer da OpenAI, mas você pode estar se perguntando por que eles escolheram esses comprimentos de token. Vamos considerar algumas outras opções de tokenização. Suponha que tentamos a implementação mais simples possível, onde cada letra é um token. Isso facilita a divisão do texto em tokens e mantém pequeno o número total de tokens diferentes. No entanto, não podemos codificar tanta informação como na abordagem da OpenAI.
Se usássemos tokens baseados em letras no exemplo acima, 11 tokens poderiam codificar apenas “Precisamos”, enquanto 11 dos tokens da OpenAI podem codificar a frase inteira. Acontece que os modelos de linguagem atuais têm um limite no número máximo de tokens que podem receber. Portanto, queremos incluir o máximo de informações possível em cada token.
Agora vamos considerar o cenário em que cada palavra é um token. Comparado à abordagem da OpenAI, precisaríamos apenas de sete tokens para representar a mesma frase, o que parece mais eficiente. E a divisão por palavra também é fácil de implementar.
No entanto, os modelos de linguagem precisam ter uma lista completa de tokens que podem encontrar, e isso não é viável para palavras inteiras — não apenas porque há muitas palavras no dicionário, mas também porque seria difícil acompanhar o domínio. terminologia específica e quaisquer novas palavras que sejam inventadas.
Portanto, não é surpreendente que a OpenAI tenha optado por uma solução em algum lugar entre esses dois extremos. Outras empresas lançaram tokenizadores que seguem uma abordagem semelhante, por exemplo, Sentence Piece do Google.
Agora que entendemos melhor os tokens, vamos voltar ao nosso diagrama original e ver se conseguimos entendê-lo um pouco melhor. Modelos generativos levamtokens, que podem ser algumas palavras, alguns parágrafos ou algumas páginas. E eles produzem um único token, que pode ser uma palavra curta ou parte de uma palavra.
Isso faz um pouco mais de sentido agora.
Mas se você já jogou com o ChatGPT da OpenAI , sabe que ele produz muitos tokens, e não um único token. Isso ocorre porque essa ideia básica é aplicada em um padrão de janela expansível. Você dáentrada de tokens, ele produz um token de saída, depois incorpora esse token de saída como parte da entrada da próxima iteração, produz um novo token de saída e assim por diante.
Esse padrão continua se repetindo até que uma condição de parada seja atingida, indicando que terminou de gerar todo o texto necessário.
Por exemplo, se eu digitar “Precisamos” como entrada para meu modelo, o algoritmo poderá produzir os resultados mostrados abaixo:

Ao brincar com o ChatGPT, você também deve ter notado que o modelo não é determinístico: se você fizer exatamente a mesma pergunta duas vezes, provavelmente obterá duas respostas diferentes. Isso ocorre porque o modelo não produz realmente um único token previsto; em vez disso, retorna uma distribuição de probabilidade sobre todos os tokens possíveis.
Em outras palavras, retorna um vetor em que cada entrada expressa a probabilidade de um determinado token ser escolhido. O modelo então faz uma amostragem dessa distribuição para gerar o token de saída.
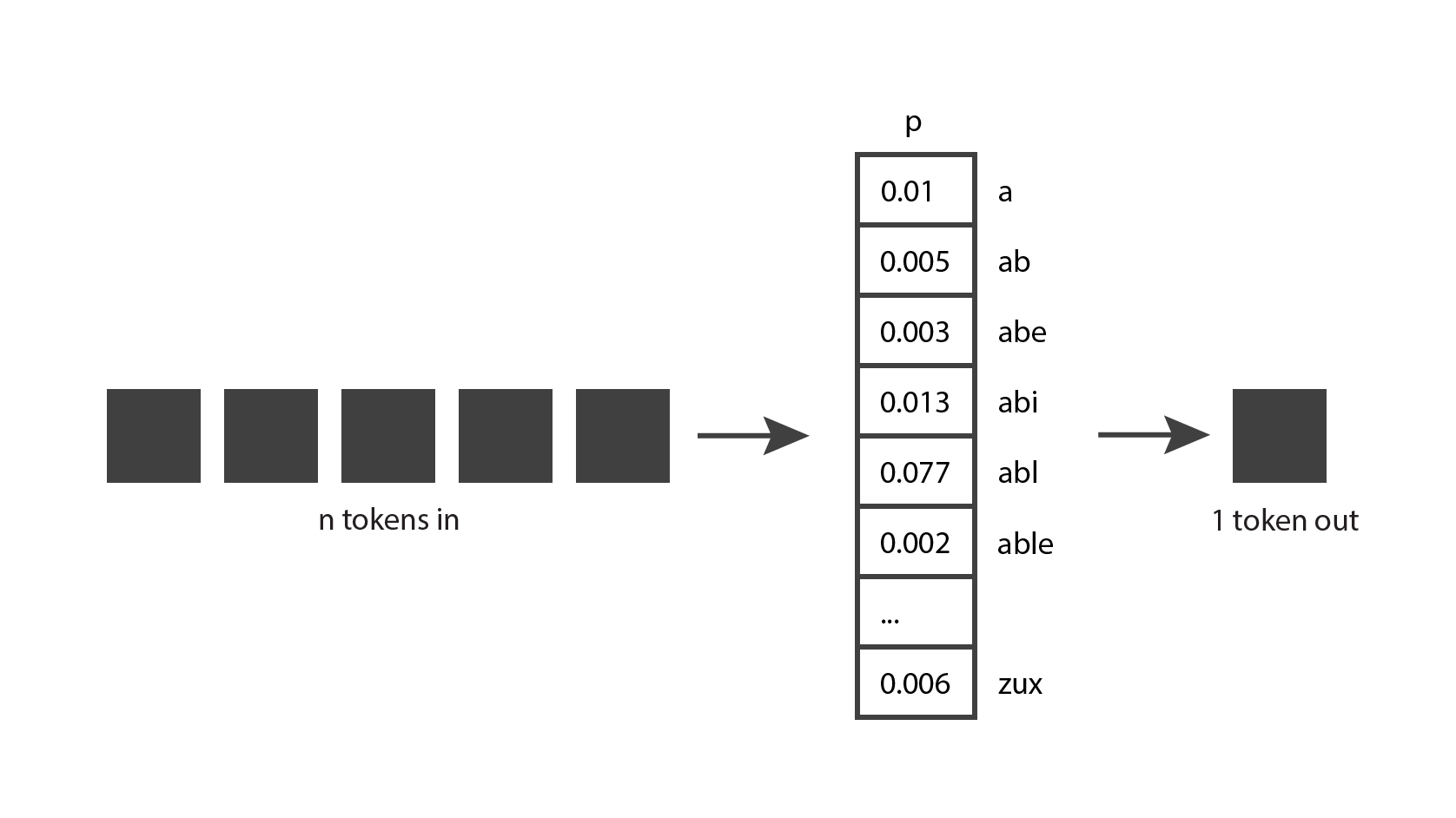
Como o modelo chega a essa distribuição de probabilidade? É para isso que serve a fase de treinamento. Durante o treinamento, o modelo é exposto a muito texto e adquire a capacidade de prever boas distribuições de probabilidade, dada uma sequência de tokens de entrada. Os modelos GPT são treinados com uma grande parte da Internet, portanto, suas previsões refletem uma combinação das informações que eles viram.
Agora você tem uma compreensão muito boa da ideia por trás dos modelos generativos. Observe que eu apenas expliquei a ideia, ainda não lhe dei um algoritmo. Acontece que essa ideia existe há muitas décadas e foi implementada usando vários algoritmos diferentes ao longo dos anos. A seguir, veremos alguns desses algoritmos.
Uma breve história dos modelos de linguagem generativa
Os Modelos Ocultos de Markov (HMMs) tornaram-se populares na década de 1970. A sua representação interna codifica a estrutura gramatical das frases (substantivos, verbos, etc.) e utilizam esse conhecimento para prever novas palavras.
Porém, por serem processos Markov, eles levam em consideração apenas o token mais recente na geração de um novo token. Então, eles implementam uma versão muito simples do ”ideia de tokens in, one token out”, onde. Como resultado, eles não geram resultados muito sofisticados. Vamos considerar o seguinte exemplo:
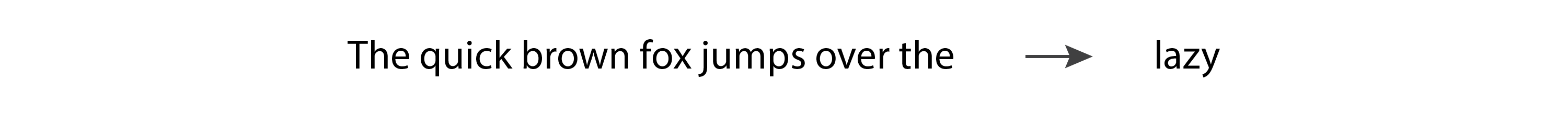
Se inserirmos “A rápida raposa marrom salta sobre” em um modelo de linguagem, esperaríamos que ele retornasse “preguiçoso”. No entanto, um HMM verá apenas o último token, “o”, e com tão poucas informações é improvável que nos dê a previsão que esperamos.
Os N-gramas tornaram-se populares na década de 1990 e, diferentemente dos HMMs, são capazes de receber alguns tokens como entrada. Um modelo de N-gramas provavelmente funcionaria muito bem na previsão da palavra “preguiçoso” para o exemplo anterior. No entanto, os N-gramas não se adaptam bem a um número maior de tokens de entrada.
Então, na década de 2000, as Redes Neurais Recorrentes (RNNs) tornaram-se bastante populares porque são capazes de aceitar um número muito maior de tokens de entrada. Em particular, LSTMs e GRUs, que são tipos de RNNs, tornaram-se amplamente utilizados e poderiam gerar resultados bastante bons. No entanto, os RNNs têm problemas de instabilidade com sequências de texto muito longas.
Os gradientes no modelo tendem a crescer exponencialmente (chamados de “gradientes explosivos”) ou diminuir até zero (chamados de “gradientes de desaparecimento”), impedindo que o modelo continue a aprender com os dados de treinamento.
Em 2017, o artigo que apresentou os Transformers foi lançado pelo Google e entramos em uma nova era na geração de texto. A arquitetura usada nos Transformers permitiu um grande aumento no número de tokens de entrada, eliminou os problemas de instabilidade de gradiente observados nas RNNs e era altamente paralelizável, o que significava que era capaz de aproveitar o poder das GPUs.
Os transformadores são baseados no “mecanismo de atenção”, onde o modelo é capaz de prestar mais atenção a algumas entradas do que a outras, independentemente de onde elas aparecem na sequência de entradas. Por exemplo, vamos considerar a seguinte frase:
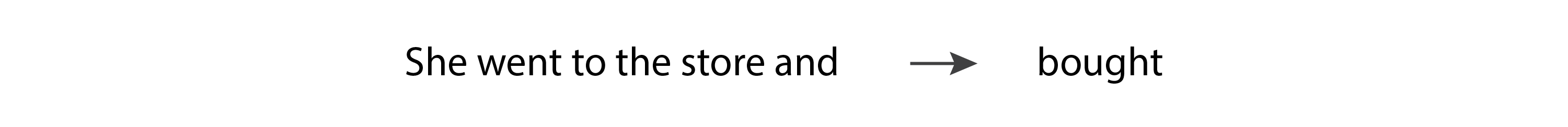
Neste cenário, quando o modelo está prevendo o verbo “comprou”, ele precisa corresponder ao pretérito do verbo “foi”. Para fazer isso, é preciso prestar muita atenção ao token “que foi”. Na verdade, ele pode prestar mais atenção ao token “foi” do que ao token “e”, apesar do fato de que “foi” aparecer mais atrás na sequência de entrada.
Os transformadores ainda são amplamente utilizados hoje e são a tecnologia escolhida pela OpenAI para seus mais recentes modelos de geração de texto. Vamos dar uma olhada mais de perto nesses modelos de linguagem.
Como os diferentes modelos GPT são implementados
No momento em que este artigo foi escrito, os três modelos de geração de texto mais recentes lançados pela OpenAI são GPT-3.5, ChatGPT e GPT-4, e todos são baseados na arquitetura Transformer. Na verdade, “GPT” significa “Transformador pré-treinado generativo”.
GPT-3.5 é um modelo de estilo de conclusão, o que significa que se fornecermos algumas palavras como entrada, ele será capaz de gerar mais algumas palavras que provavelmente as seguirão nos dados de treinamento.
O ChatGPT, por outro lado, é um modelo de estilo conversação, o que significa que tem melhor desempenho quando nos comunicamos com ele como se estivéssemos conversando. É baseado no mesmo modelo básico de transformador do GPT-3.5, mas é ajustado com dados de conversação. Em seguida, é aprimorado ainda mais usando Aprendizado por Reforço com Feedback Humano (RLHF), que é uma técnica que a OpenAI introduziu em seu artigo InstructGPT de 2022 . ‘
Nesta técnica, damos ao modelo a mesma entrada duas vezes, obtemos duas saídas diferentes e perguntamos a um classificador humano qual saída ele prefere. Essa escolha é então realimentada no modelo por meio de ajuste fino. Esta técnica traz alinhamento entre os resultados do modelo e as expectativas humanas e é crítica para o sucesso dos modelos mais recentes da OpenAI.
O GPT-4 , por outro lado, pode ser usado tanto para conclusão quanto para conversação, e possui seu próprio modelo básico totalmente novo. Este modelo básico também é ajustado com RLHF para melhor alinhamento com as expectativas humanas.


