Se os modelos treinados em dados deveriam ser objetivos e imparciais, como esses algoritmos erraram tanto? Esse preconceito pode ser corrigido?
Desde assistentes de voz ao reconhecimento de imagens, da detecção de fraudes aos feeds de redes sociais, a aprendizagem automática (ML) e a inteligência artificial (IA) estão a tornar-se uma parte cada vez mais importante da sociedade. Os dois campos fizeram enormes progressos nos últimos anos graças aos ganhos no poder computacional e à chamada “explosão de informação”. Tais algoritmos estão a ser utilizados em campos tão variados como a medicina, a agricultura, os seguros, os transportes e a arte, e o número de empresas que se apressam a abraçar o que o ML e a IA podem oferecer aumentou rapidamente nos últimos anos.
De acordo com um inquérito realizado pela Teradata em Julho de 2023, 80% das empresas já começaram a investir em tecnologias de IA e 30% planeiam aumentar os seus gastos nos próximos 36 meses. Prevê -se também que o investimento nestes modelos cresça de 12 mil milhões de dólares em 2023 para mais de 50 mil milhões de dólares em 2023. Considerados mais precisos, consistentes e objectivos do que o julgamento humano, as promessas e expectativas sobre o que o ML e a IA podem alcançar nunca foram tão grandes.
A inteligência artificial e o aprendizado de máquina são frequentemente usados de forma intercambiável, mas na verdade existem diferenças entre os dois.

A inteligência artificial refere-se à ciência mais ampla de fazer com que os computadores atuem de forma inteligente, sem serem explicitamente programados.
O aprendizado de máquina é o uso de algoritmos estatísticos para detectar padrões em grandes conjuntos de dados. É uma maneira pela qual os computadores podem se tornar melhores em uma tarefa e, portanto, considerados um subconjunto da inteligência artificial.
No entanto, para cada rede neural que pode derrotar os campeões do Jeopardy e superar os mestres do Go, existem outros casos bem documentados em que esses algoritmos produziram resultados altamente perturbadores. Descobriu-se que os programas de análise facial apresentam uma taxa de erro de 20 a 34 por cento ao tentar determinar o género das mulheres afro-americanas, em comparação com uma taxa de erro inferior a 1 por cento para os homens brancos. Os algoritmos de ML usados para prever quais criminosos têm maior probabilidade de reincidir tendem a sinalizar incorretamente os réus negros como sendo de alto risco, com o dobro da taxa dos réus brancos. Um modelo de incorporação de palavras usado para ajudar as máquinas a determinar o significado das palavras com base em sua semelhança também associou os homens a programadores de computador e as mulheres a donas de casa .
Se os modelos treinados em dados deveriam ser objetivos e imparciais, como esses algoritmos erraram tanto? Esse preconceito pode ser corrigido?
O pipeline de aprendizado de máquina
Ser capaz de usar dados para responder perguntas de forma significativa por meio de aprendizado de máquina requer várias etapas. Antes de entrar nos detalhes do preconceito, é importante entendê-los.
- Coleta de dados. Todos os modelos de aprendizado de máquina requerem dados como entradas. No mundo cada vez mais digitalizado de hoje, os dados podem ser derivados de diversas fontes, incluindo interações do usuário em um site, coleções de imagens fotográficas e gravações de sensores.
- Preparação de dados. Os dados coletados raramente estão em um estado utilizável como estão. Os dados muitas vezes precisam ser limpos, transformados e verificados quanto a erros antes de estarem prontos para serem inseridos em um modelo.
- Divida o conjunto de dados em conjuntos de treinamento e teste. O conjunto de dados de treinamento é usado para construir e treinar o modelo, enquanto o conjunto de dados de teste, que é mantido separado, é usado para avaliar o desempenho do modelo. É importante avaliar o modelo com base em dados que não tenha visto antes, a fim de garantir que realmente aprendeu algo sobre a estrutura subjacente dos dados, em vez de simplesmente “memorizar” os dados de treino.
- Ajustar e treinar modelos. Esta é a etapa onde vários tipos de modelos de ML, como modelos de regressão, florestas aleatórias e redes neurais, são construídos e aplicados aos dados de treinamento. Os modelos são iterados fazendo pequenos ajustes em seus parâmetros para melhorar seu desempenho com o objetivo de gerar as previsões mais precisas possíveis.
- Avalie o modelo no conjunto de dados de teste. O modelo de melhor desempenho é usado nos dados de teste para ter uma ideia de como o modelo funcionará em dados do mundo real nunca vistos antes. Com base nos resultados, podem ser necessários mais refinamentos e ajustes do modelo.
- Fazer previsões ! Uma vez finalizado o modelo, ele pode começar a ser usado para responder à pergunta para a qual foi projetado.
Fontes de preconceito
Existem duas maneiras principais pelas quais o preconceito pode ser introduzido e amplificado durante o processo de aprendizado de máquina: usando dados não representativos e durante o ajuste e treinamento de modelos.
Dados tendenciosos
Dados não representativos e tendenciosos.
Quando se examina uma amostra de dados, é imperativo verificar se a amostra é representativa da população de interesse. Uma amostra não representativa, onde alguns grupos estão sobre ou sub-representados, introduz inevitavelmente preconceitos na análise estatística. Um conjunto de dados pode não ser representativo devido a erros de amostragem e erros de não amostragem.
Erros de amostragem referem-se à diferença entre um valor populacional e uma estimativa amostral que existe apenas por causa da amostra que foi selecionada. Os erros de amostragem são especialmente problemáticos quando o tamanho da amostra é pequeno em relação ao tamanho da população. Por exemplo, suponhamos que amostramos 100 residentes para estimar a renda familiar média nos EUA. Uma amostra que incluísse Jeff Bezos resultaria numa sobrestimativa, enquanto uma amostra que incluísse predominantemente famílias de baixos rendimentos resultaria numa subestimativa.
Média populacional: $ 10.000
Os erros não relacionados com a amostragem são normalmente mais graves e podem surgir de muitas fontes diferentes, tais como erros na recolha de dados, não resposta e viés de seleção. Exemplos típicos incluem perguntas de coleta de dados mal formuladas, coleta de dados somente na web que deixam de fora pessoas que não têm acesso fácil à internet, representação excessiva de pessoas que têm sentimentos particularmente fortes sobre um assunto e respostas que podem não refletir a opinião de alguém. opinião verdadeira .
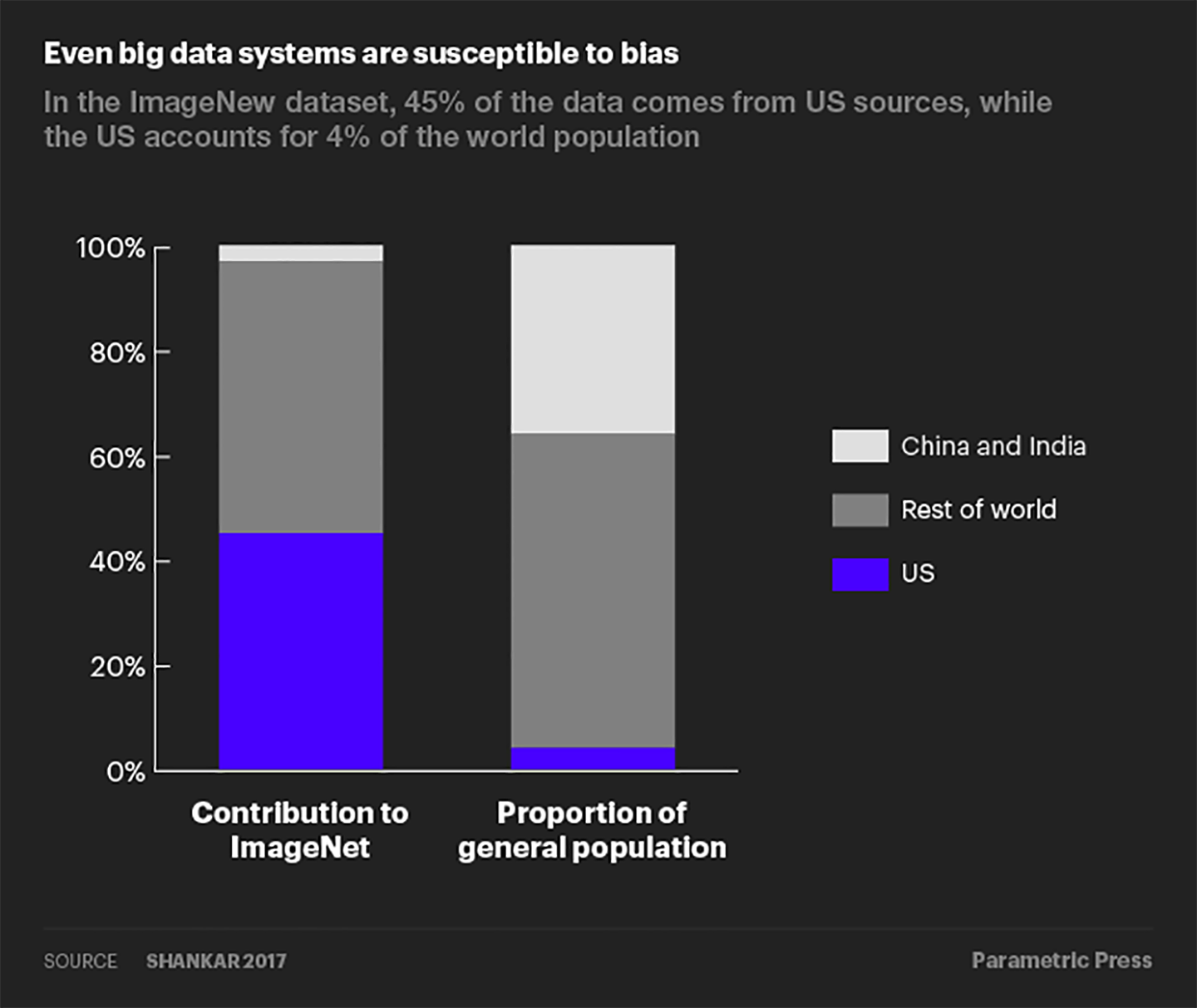
Mesmo o big data é suscetível a erros de não amostragem. Um estudo realizado por pesquisadores do Google descobriu que os Estados Unidos (que respondem por 4% da população mundial) contribuíram com mais de 45% dos dados para o ImageNet, um banco de dados com mais de 14 milhões de imagens rotuladas. Entretanto, a China e a Índia juntas contribuem com apenas 3% das imagens, apesar de representarem mais de 36% da população mundial.
Como resultado dessa distribuição distorcida de dados, os algoritmos de classificação de imagens que usam o banco de dados ImageNet muitas vezes rotulariam corretamente uma imagem de uma noiva tradicional dos EUA com palavras como “noiva” e “casamento”, mas rotulariam uma imagem de uma noiva indiana com palavras como “ fantasia”.
Dados representativos, mas ainda tendenciosos.
E se um conjunto de dados for representativo da sua população-alvo? Não há mais preocupações com o preconceito nos dados, certo? Não tão rápido – um conjunto de dados representativo ainda pode ser tendencioso na medida em que reflete qualquer preconceito social histórico. Descobriu-se que um algoritmo de recrutamento usado pela Amazon favorecia desproporcionalmente candidatos do sexo masculino. Os dados utilizados para treinar o algoritmo foram baseados em currículos coletados ao longo de um período de 10 anos.
Como a indústria tecnológica foi historicamente dominada por homens, a maioria dos currículos foi enviada por homens. Portanto, embora o conjunto de dados fosse “representativo” do conjunto histórico de candidatos, capturou o preconceito de género inerente e transmitiu-o ao algoritmo de recrutamento.
Dados representativos, mas tendenciosos, são, em certo sentido, uma questão mais problemática do que dados não representativos, uma vez que a correção dos primeiros exigiria a abordagem de preconceitos inerentes à sociedade.
Vieses que são amplificados por meio de algoritmos

Os próprios algoritmos de aprendizado de máquina podem amplificar o viés se fizerem previsões mais distorcidas do que os dados de treinamento. Essa amplificação ocorre frequentemente através de dois mecanismos: 1) incentivos para prever observações como pertencentes ao grupo maioritário e 2) ciclos de feedback descontrolados.
Algoritmos incentivados a prever o grupo majoritário.
A fim de maximizar a precisão preditiva quando confrontados com um conjunto de dados desequilibrado, os algoritmos de aprendizagem automática são incentivados a colocar mais peso de aprendizagem no grupo maioritário, prevendo assim desproporcionalmente que as observações pertençam a esse grupo maioritário. O próximo exemplo interativo ilustra essa tendência.
Suponha que temos um algoritmo de classificação de imagens encarregado de identificar o gênero da pessoa em uma determinada imagem. O conjunto de dados de treinamento contém 10 imagens de culinária; cada imagem mostra um homem ou uma mulher na cozinha. Este conjunto de dados pode variar desde uma amostra equilibrada e imparcial (cinco imagens mostrando homens, cinco imagens mostrando mulheres) até uma amostra completamente tendenciosa (todas as 10 imagens mostrando mulheres ou homens).
Ter dados de formação imparciais é o cenário ideal, mas num cenário mais realista, as mulheres provavelmente estarão sobre-representadas numa amostra de imagens culinárias. Suponha que o conjunto de dados de treinamento contenha oito imagens de mulheres cozinhando e duas imagens de homens e que o modelo tenha uma precisão preditiva de 70% (ou seja, um viés de 80/20 e uma precisão do modelo de 70% no interativo abaixo). Quando esses dados são alimentados pelo modelo, o modelo rotula corretamente o gênero de seis fotos de mulheres e uma das fotos de um homem, enquanto confunde o gênero das três fotos restantes (taxa de erro de 30%).
Se, em vez disso, o modelo simplesmente previsse que todas as imagens de cozinha são de uma mulher, reduziria a sua taxa de erro para 20% porque rotulou corretamente todas as fotos com uma mulher, confundindo apenas o género das duas fotos de homens. Na busca por maior precisão preditiva, o modelo ampliou o viés de 80% de mulheres nos dados de treinamento para 100% de mulheres na previsão do modelo.
Experimente as configurações de tendência e precisão do modelo abaixo para ver como diferentes mixagens afetam a tendência do modelo de amplificar a tendência. Para um determinado nível de precisão preditiva, como a tendência do modelo de amplificar o viés muda com a quantidade de viés nos dados e vice-versa? Quando o modelo é incentivado a amplificar o preconceito e quando não é?
Ciclos de feedback descontrolados.
No exemplo anterior de classificação de imagens, a amplificação de polarização para no estágio de previsão do modelo. No entanto, em modelos de aprendizado de máquina em que a previsão é realimentada no modelo como entradas para a próxima rodada de previsões, o viés pode ser amplificado ainda mais na forma de um ciclo de feedback.
Considere um algoritmo de policiamento preditivo usado para determinar a alocação ideal da força policial em uma cidade. Suponha que a cidade tenha duas delegacias (A e B) e um policial, John. A cidade deseja usar dados históricos sobre ocorrências de crimes anteriores para determinar para qual delegacia enviar John. O objetivo é enviar John a cada delegacia em proporção à frequência de crimes que ocorrem em cada delegacia. Se 40% dos crimes ocorrerem na delegacia A, o algoritmo deverá enviar John para patrulhar A 40% do tempo.
Em nosso exemplo, digamos que a cidade sofreu um total de 22 crimes no ano passado, com 12 deles ocorrendo na delegacia A e 10 na delegacia B, conforme mostrado abaixo:
 O algoritmo preditivo usa esses dados históricos para determinar para onde enviar John. A probabilidade de o algoritmo despachar John para a delegacia A é proporcional à parcela de todos os crimes que ocorreram em A. Nesse caso, essa probabilidade é 22/12 = 54,5%. O algoritmo escolherá enviar John para a delegacia B com probabilidade de 22/10 = 45,5%.
O algoritmo preditivo usa esses dados históricos para determinar para onde enviar John. A probabilidade de o algoritmo despachar John para a delegacia A é proporcional à parcela de todos os crimes que ocorreram em A. Nesse caso, essa probabilidade é 22/12 = 54,5%. O algoritmo escolherá enviar John para a delegacia B com probabilidade de 22/10 = 45,5%.
Digamos que o algoritmo decida enviar John para patrulhar a delegacia A. Enquanto está lá, John encontra três crimes e os registra no sistema. Os dados actualizados mostram agora um total de 15 crimes passados em A e 10 em B. No entanto, como ninguém foi enviado para a esquadra B, os crimes que ocorreram em B no mesmo dia não foram capturados nos dados.
 No dia seguinte, quando o algoritmo decidir para onde enviar John, ele terá 15/25 = 60% de probabilidade de enviar John para A e 10/25 = 40% de probabilidade de enviá-lo para B. O algoritmo agora tem um par maior probabilidade de enviar John para a delegacia A como resultado de sua decisão de designar John para A ontem. Quando o modelo opta por enviar John para a delegacia A, mais ocorrências de crimes serão registradas para a delegacia A, enquanto os crimes que ocorrem em B são ignorados e permanecem não capturados nos dados.
No dia seguinte, quando o algoritmo decidir para onde enviar John, ele terá 15/25 = 60% de probabilidade de enviar John para A e 10/25 = 40% de probabilidade de enviá-lo para B. O algoritmo agora tem um par maior probabilidade de enviar John para a delegacia A como resultado de sua decisão de designar John para A ontem. Quando o modelo opta por enviar John para a delegacia A, mais ocorrências de crimes serão registradas para a delegacia A, enquanto os crimes que ocorrem em B são ignorados e permanecem não capturados nos dados.
Com o tempo, os dados tornar-se-ão cada vez mais distorcidos, com a diferença entre a taxa de criminalidade observada e a taxa de criminalidade real dos dois distritos a alargar-se devido às decisões tomadas pelo modelo.
AB
Os ciclos de feedback são especialmente problemáticos quando os subgrupos nos dados de formação apresentam grandes diferenças estatísticas (por exemplo, um distrito tem uma taxa de criminalidade muito mais elevada do que outros); um modelo treinado com base em tais dados “fugirá” rapidamente e fará previsões que se enquadram apenas no grupo majoritário, gerando assim dados cada vez mais desequilibrados que são realimentados no modelo.
Mesmo quando os subgrupos são estatisticamente semelhantes, os ciclos de feedback ainda podem levar a previsões ruidosas e menos precisas. Algoritmos em que o resultado preditivo determina qual feedback o algoritmo recebe – por exemplo, previsão de reincidência, tradução de idiomas e feeds de notícias de mídia social – devem sempre ser monitorados diligentemente quanto à presença de viés de ciclos de feedback.
Viés nos dados e nos algoritmos estão inter-relacionados
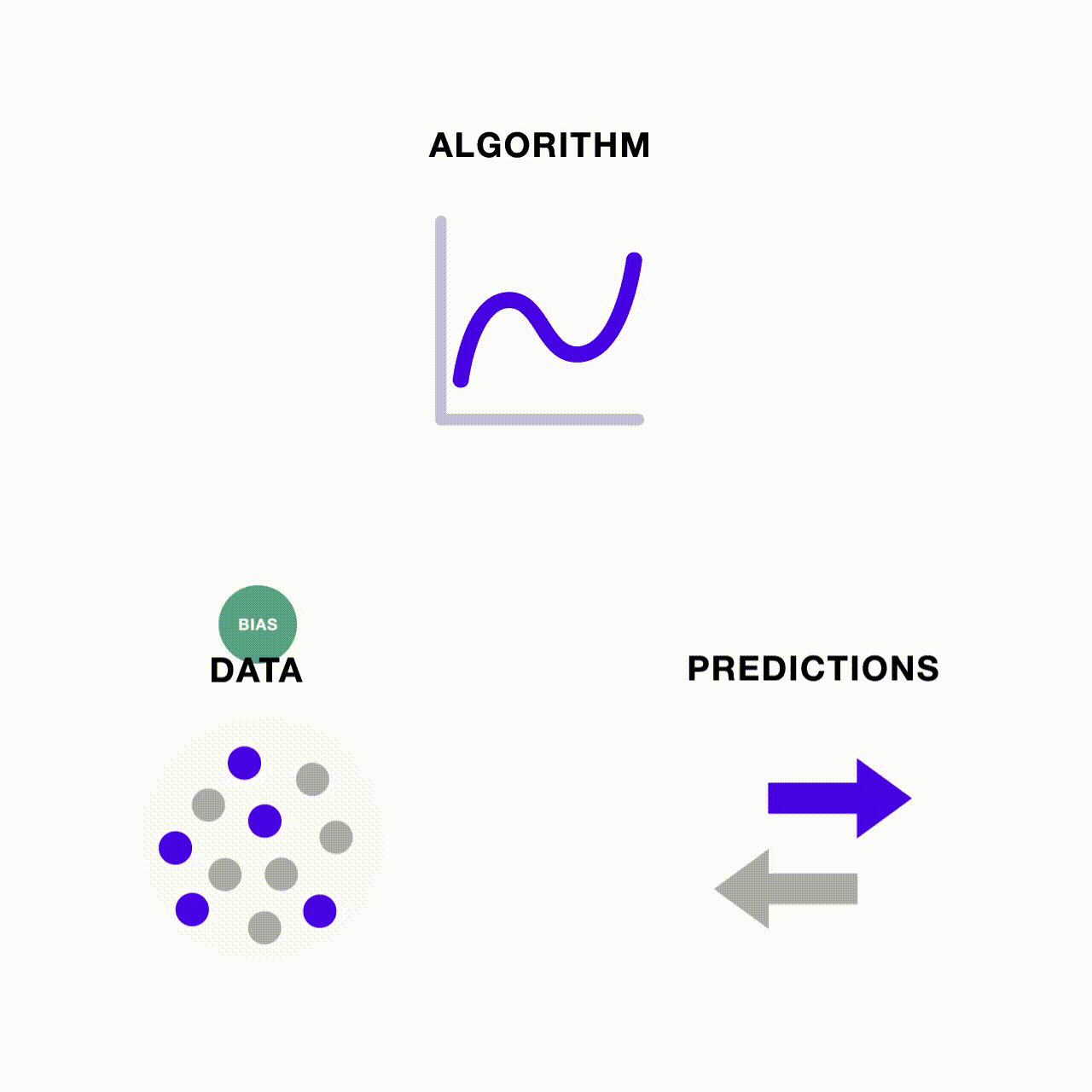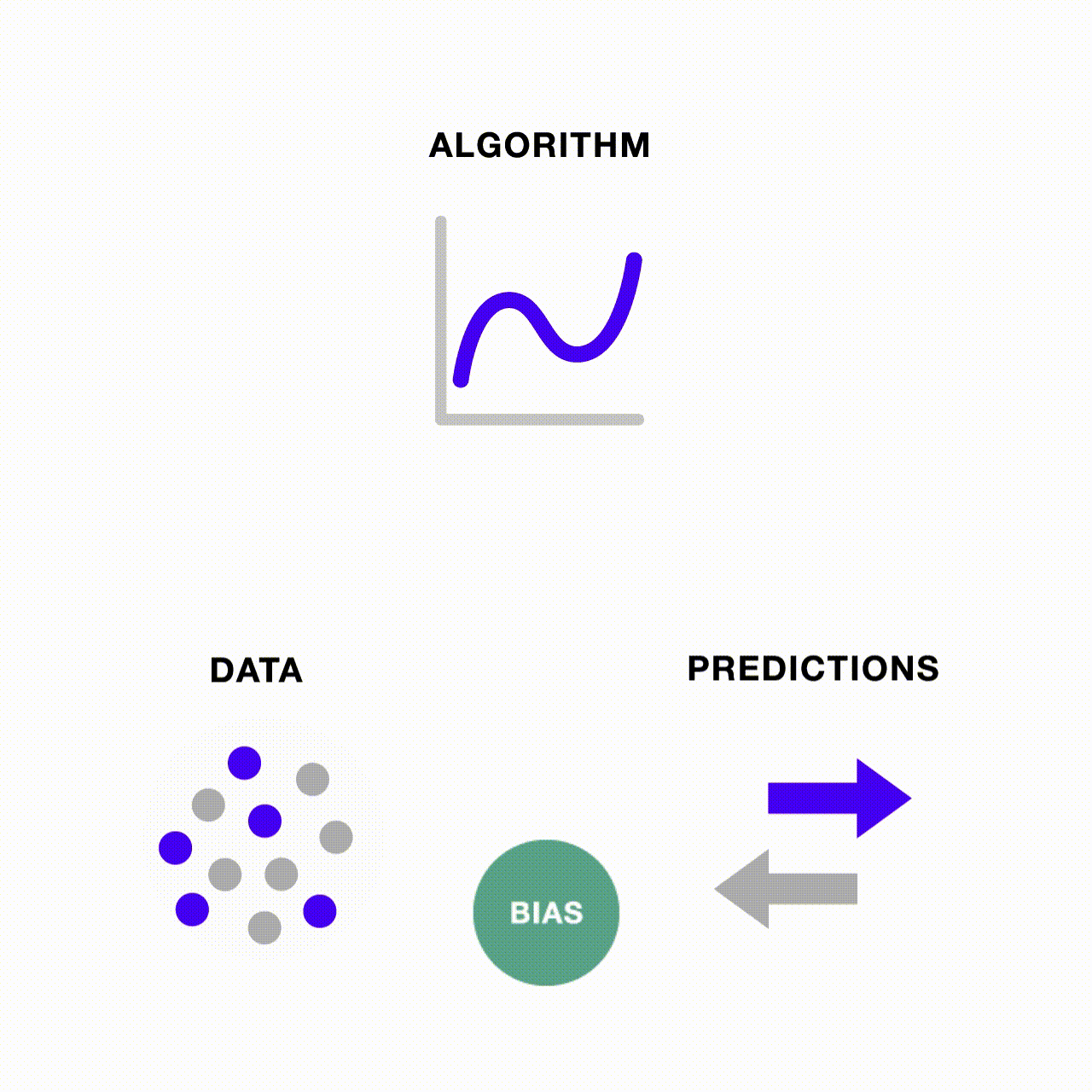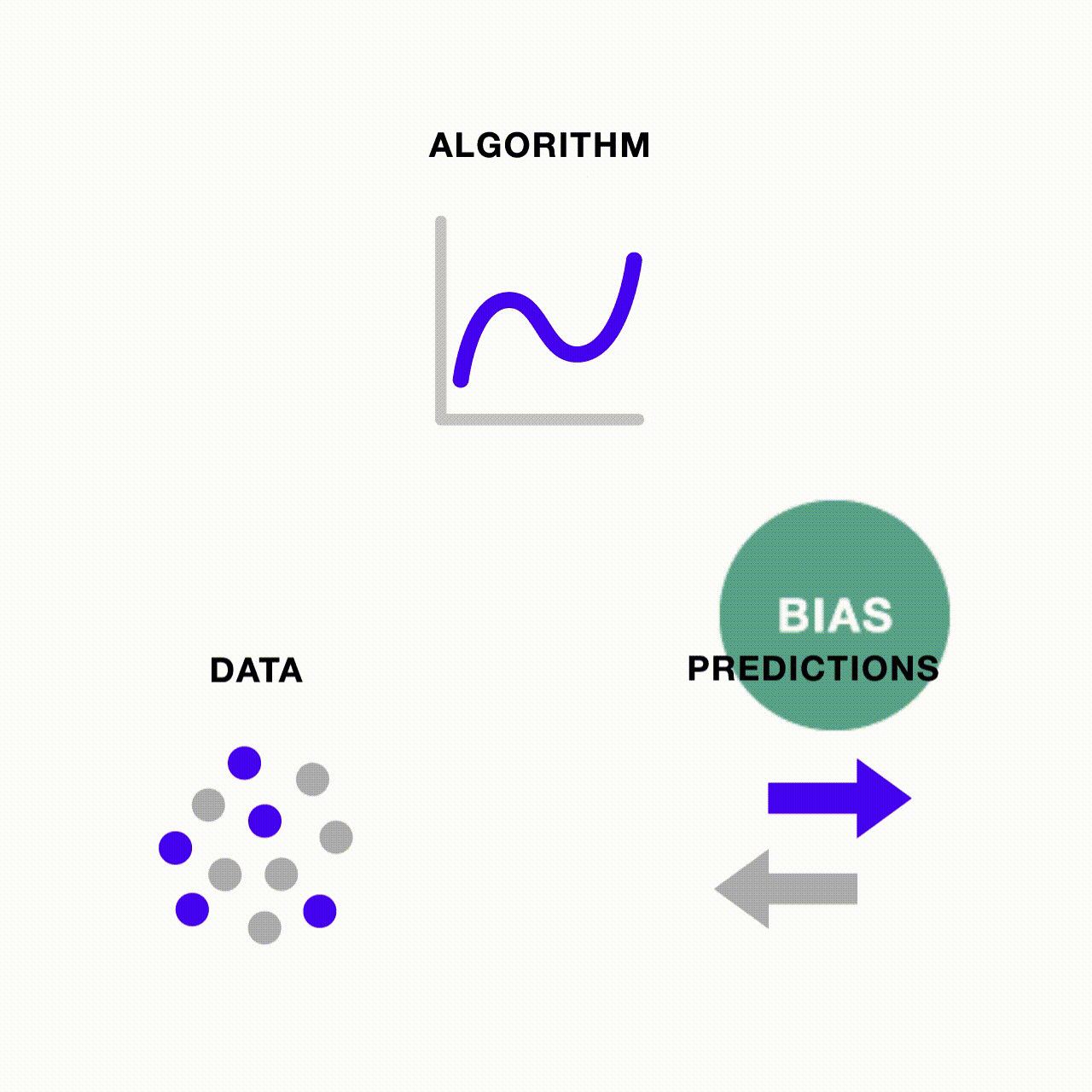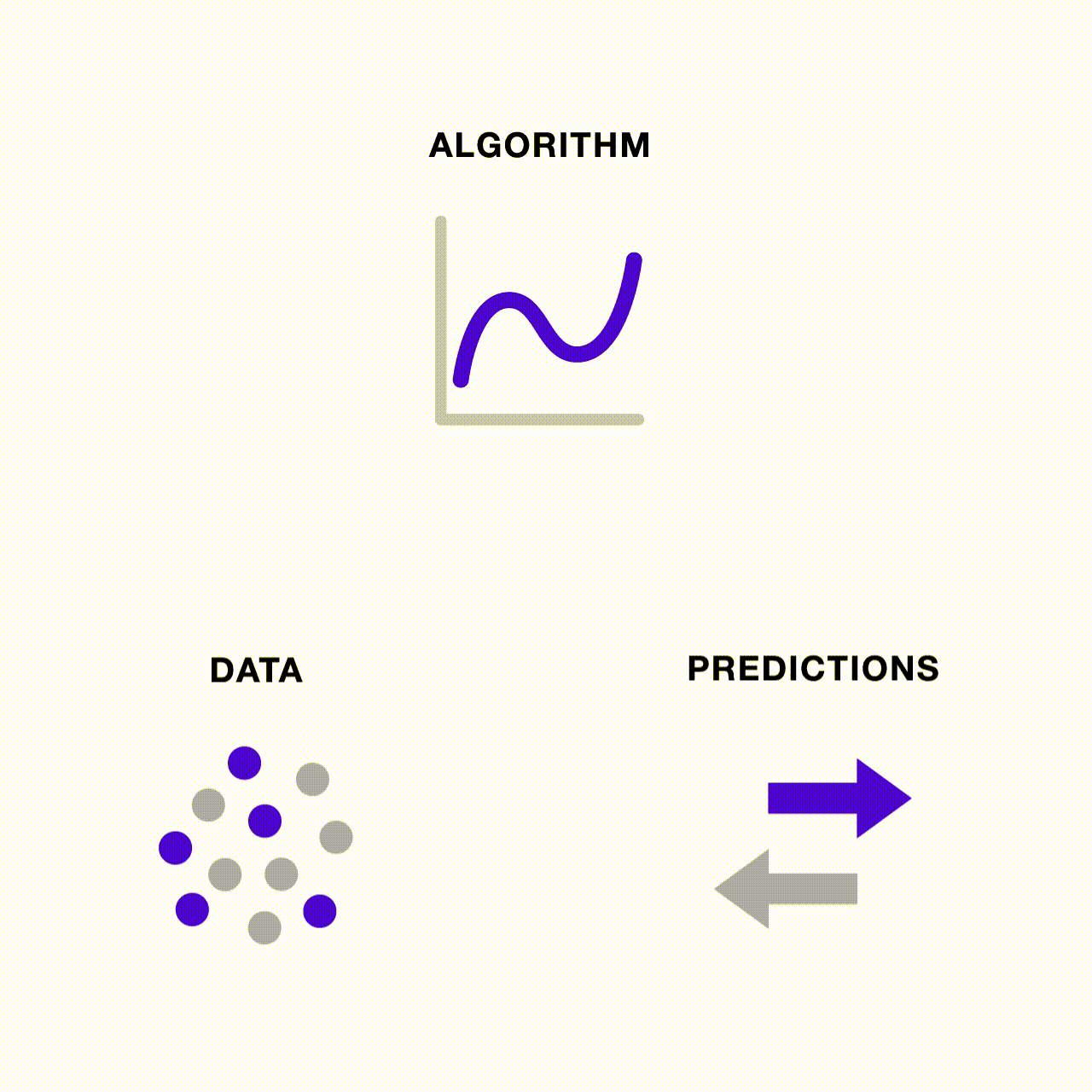
A esta altura, deve estar claro que os preconceitos nos dados e nos algoritmos estão inter-relacionados. Quando um algoritmo é alimentado com dados de treinamento onde um grupo domina a amostra, ele é incentivado a priorizar o aprendizado sobre o grupo dominante e a prever excessivamente o número de observações que pertencem ao grupo dominante. Esta tendência é exacerbada quando a precisão preditiva do modelo é relativamente baixa. Por outro lado, se os dados fossem equilibrados em relação à precisão preditiva, o modelo não teria nada a ganhar com a previsão excessiva do grupo dominante.
O preconceito também pode ser perpetuado através de um ciclo de feedback se as próprias previsões tendenciosas do modelo forem repetidamente realimentadas nele, tornando-se sua própria fonte de dados tendenciosa para a próxima rodada de previsões. No contexto de aprendizado de máquina, não enfrentamos mais apenas o risco de lixo entrar e sair lixo – quando há lixo entrando, mais e mais lixo pode ser gerado através do pipeline de ML se não monitorarmos e abordarmos possíveis fontes de preconceito.
Como as pessoas estão lidando com o preconceito
Como realmente lidar com o preconceito no pipeline de ML? Embora uma solução adequada dependa de cada circunstância específica, aqui estão algumas maneiras pelas quais as empresas e os pesquisadores estão tentando reduzir o preconceito no aprendizado de máquina.
1 . Dados de despolarização
Uma chave para eliminar o viés dos dados é garantir que uma amostra representativa seja coletada em primeiro lugar. O preconceito causado por erros de amostragem pode ser mitigado através da recolha de amostras maiores e da adopção de técnicas de recolha de dados, como a amostragem aleatória estratificada. Embora os erros de amostragem não desapareçam totalmente, o rápido crescimento dos dados — 2,5 quintilhões de bytes por dia e continua aumentando — e a crescente capacidade de coleta de dados tornaram mais fácil do que nunca mitigar os erros de amostragem em comparação com o passado.
Os preconceitos resultantes de erros não amostrais são muito mais variados e mais difíceis de resolver, mas ainda se deve esforçar-se por minimizar estes tipos de erros através de meios como a formação adequada, o estabelecimento de um objectivo e procedimento claros para a recolha de dados e a realização de uma validação cuidadosa dos dados. Por exemplo, em resposta à base de dados de classificação de imagens que continha desproporcionalmente poucas imagens de casamento da Índia, o Google procurou deliberadamente contribuições da Índia para tornar a base de dados mais representativa.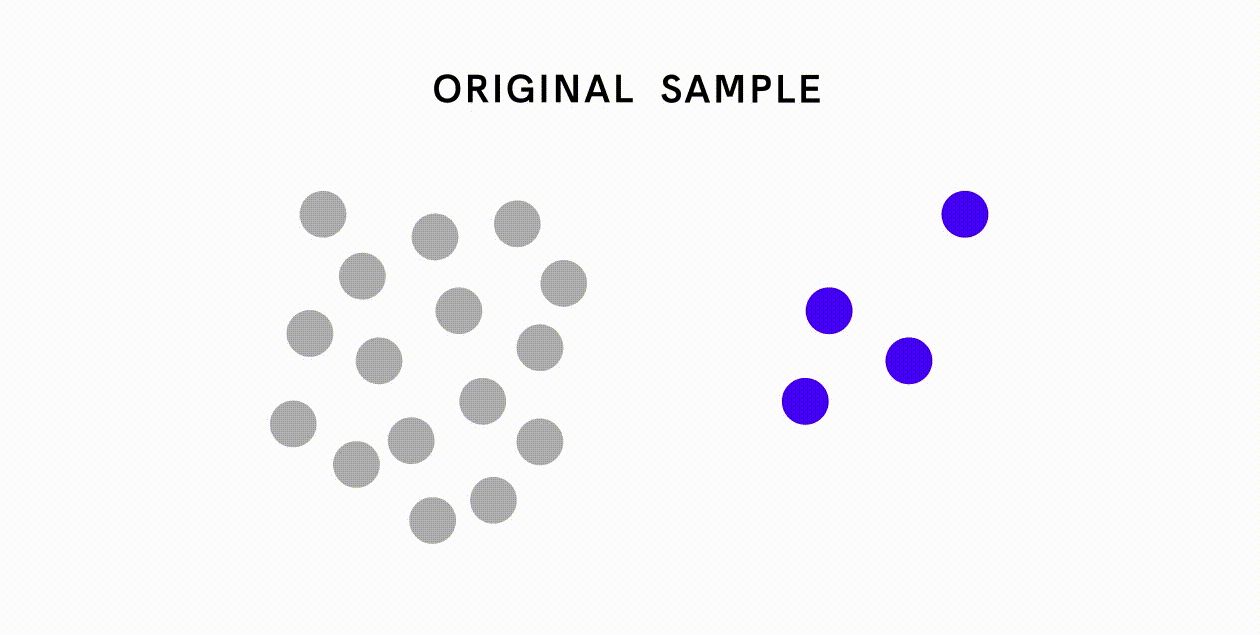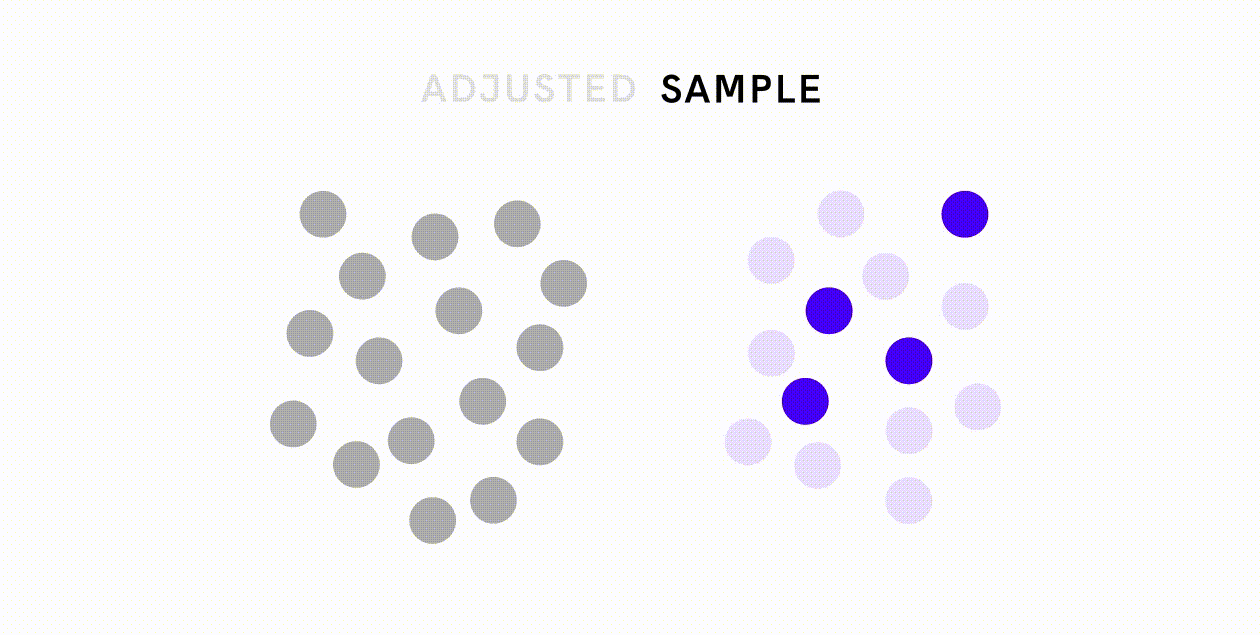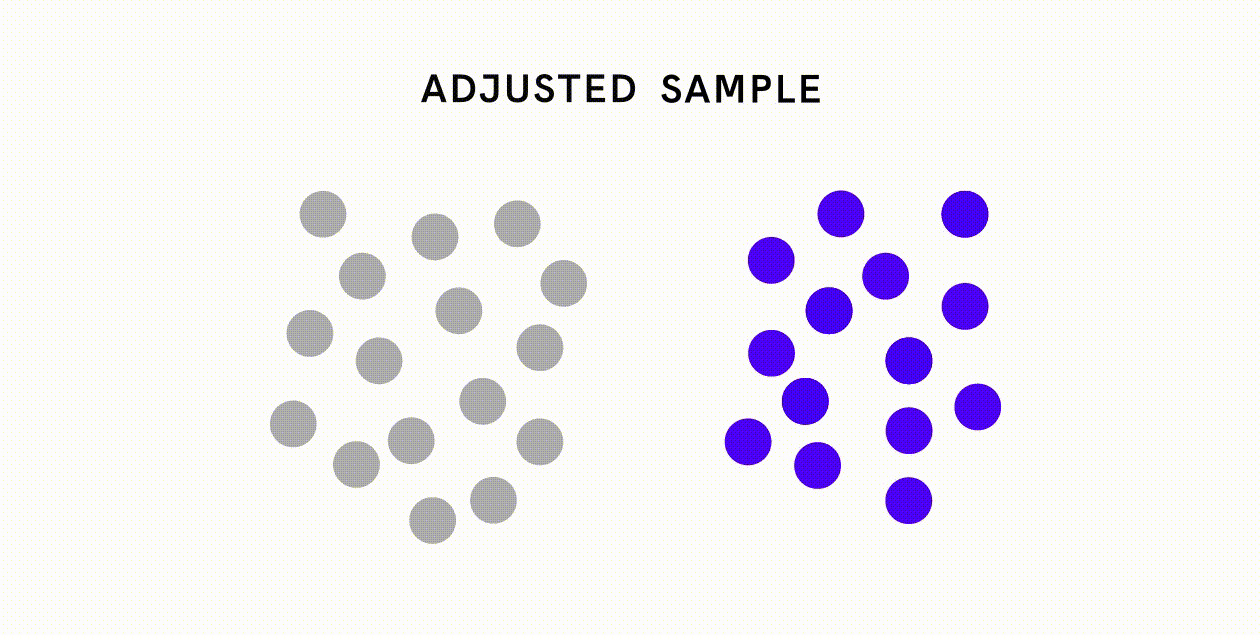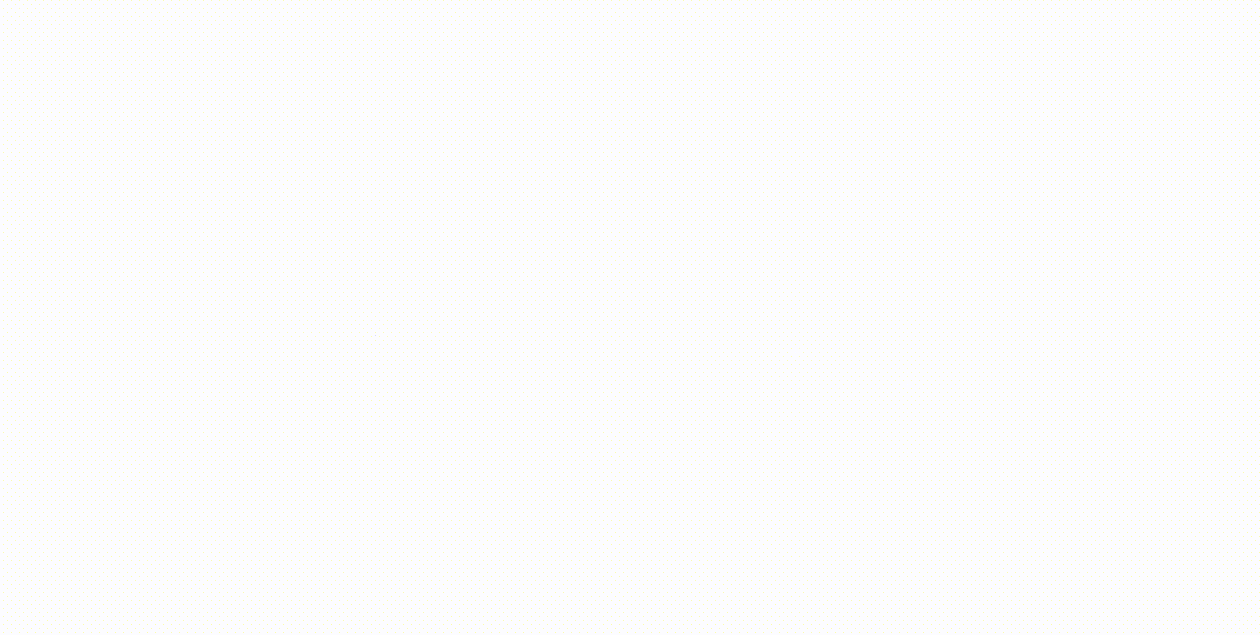
E quanto aos dados que são representativos, mas que refletem preconceitos inerentes à população? Para conjuntos de dados que contêm grupos minoritários, pode-se fazer uma amostragem excessiva desses grupos minoritários para criar um conjunto de dados de treinamento mais equilibrado. Para conjuntos de dados que podem conter associações tendenciosas, pode-se primeiro quantificar e remover quaisquer associações tendenciosas do conjunto de dados antes de prosseguir para os estágios de treinamento e previsão do modelo.
Word2Vec é um modelo que pode ser usado para quantificar relações entre palavras. A eliminação de preconceitos dos dados do Word2Vec é um exemplo desta última abordagem: os investigadores mediram primeiro o quão próximas duas palavras se relacionam entre si ao longo da dimensão de género e avaliaram se diferentes forças de associação reflectem preconceitos de género ou relações apropriadas.
Por exemplo, o facto de “mulher” estar mais intimamente relacionada com “dona de casa” em oposição a “programadora de computador” é indicativo de preconceito de género, enquanto uma associação estreita entre “mulher” e “rainha” reflecte uma relação apropriada e de definição. Os pesquisadores então implementaram um algoritmo separado para neutralizar a associação de gênero entre pares de palavras que exibiam preconceito de gênero antes de alimentar esses dados desviados no algoritmo de incorporação Word2Vec.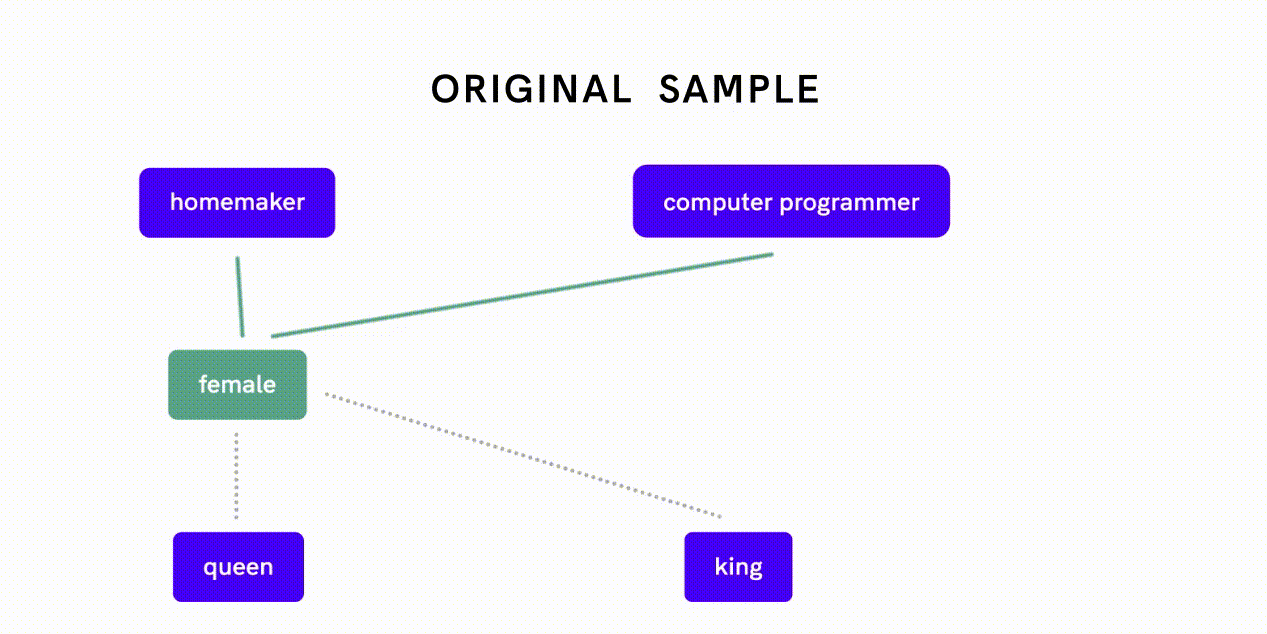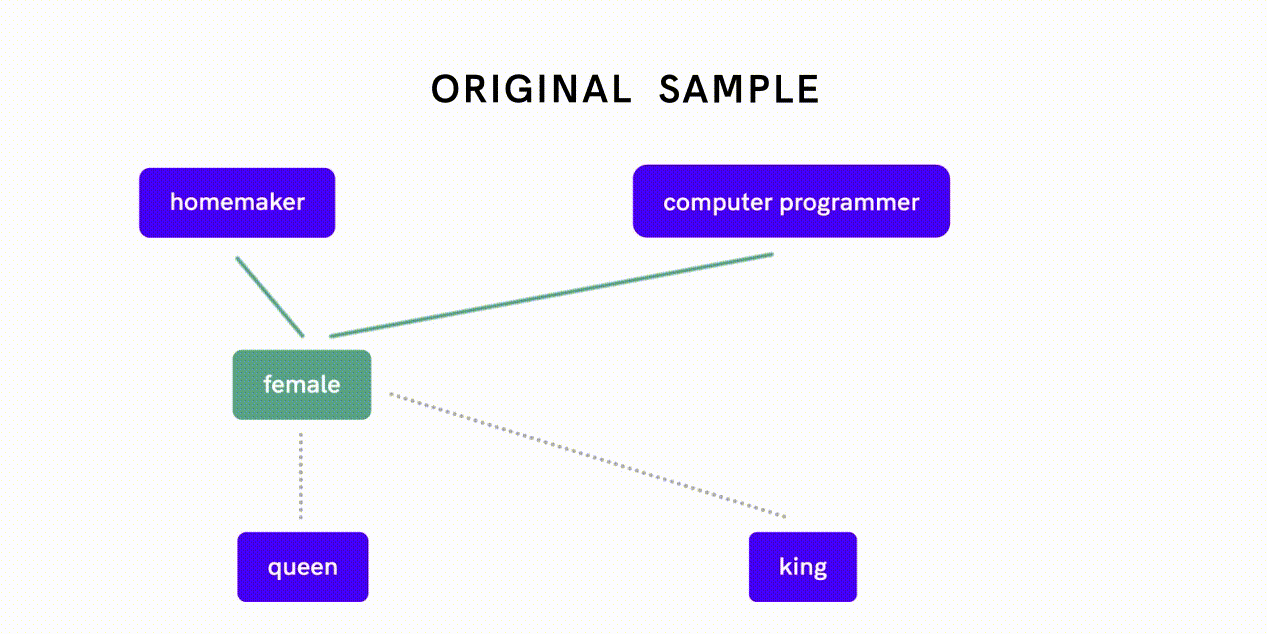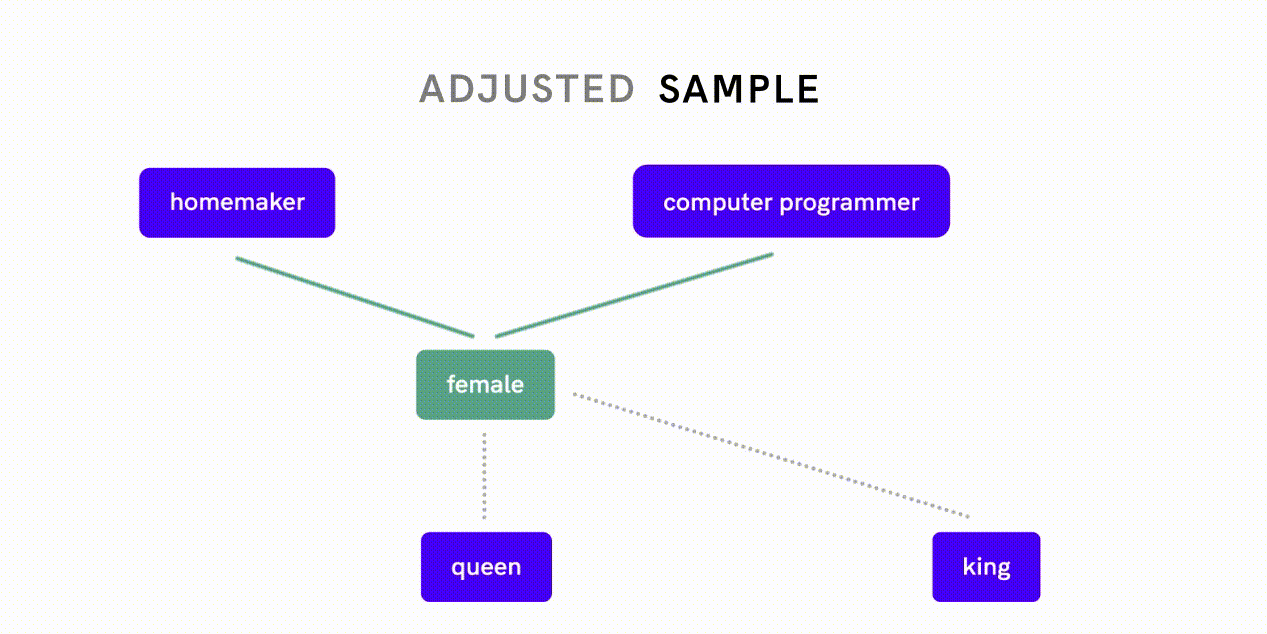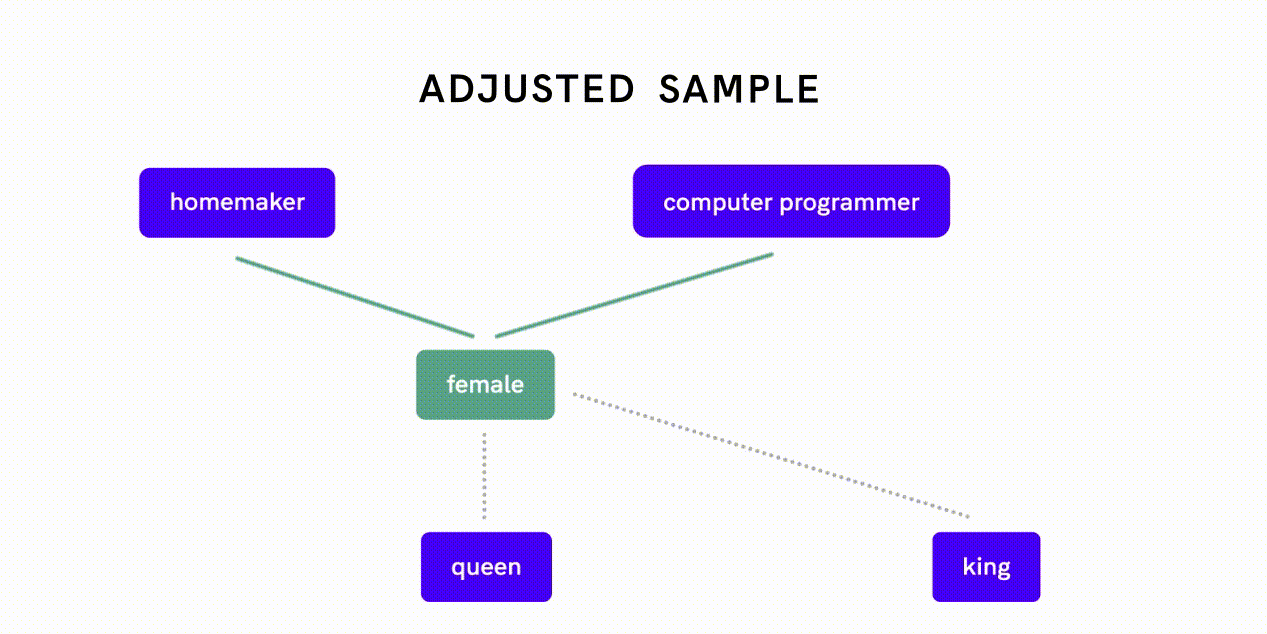
2 . Algoritmos de despolarização
Além de desviar os dados, pode-se aplicar intervenções de modelo para compensar diretamente a tendência dos algoritmos de amplificar o viés. Um método de intervenção é impor restrições ao modelo que especificam a distribuição estatística das previsões. Por exemplo, os pesquisadores conseguiram reduzir a amplificação de viés em algoritmos de rotulagem de imagens em quase 50%, adicionando restrições de modelo que exigiam que a proporção de imagens previstas como masculinas versus femininas ficasse dentro de 5% da proporção observada no conjunto de dados de treinamento. Esta abordagem pode ser particularmente útil para reduzir a amplificação de viés quando se usa conjuntos de dados de treinamento desequilibrados.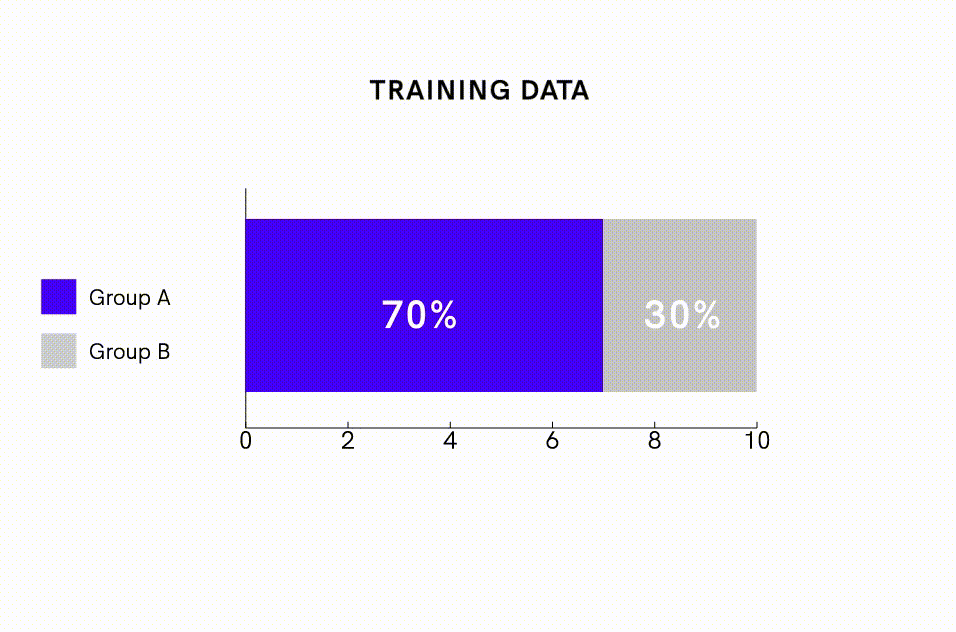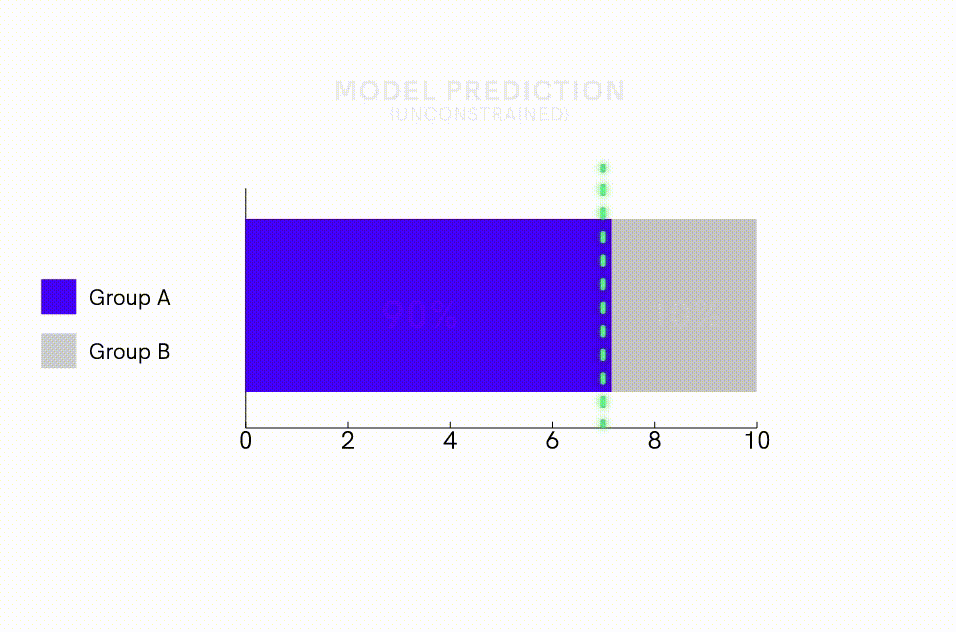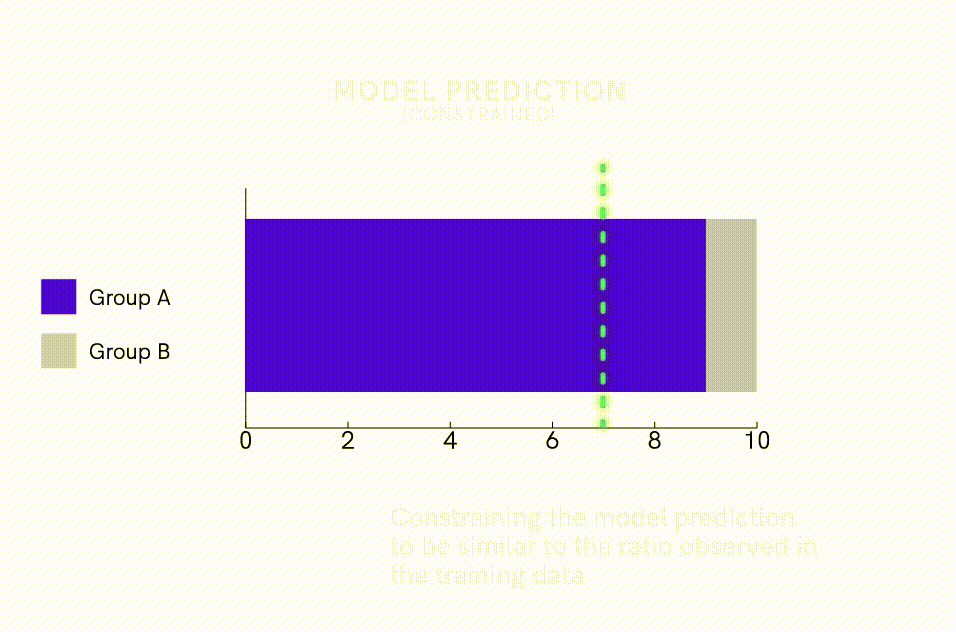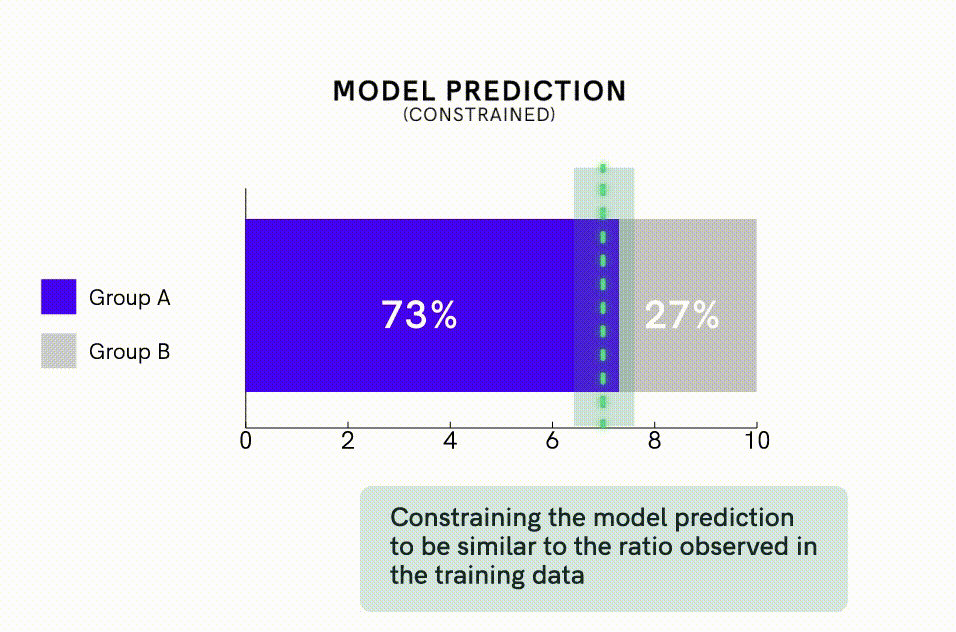
Outro método de intervenção que é particularmente útil para combater os ciclos de feedback é impor regras de amostragem que especifiquem como os resultados gerados a partir das previsões do modelo devem ser realimentados no algoritmo. Voltando ao exemplo do policiamento preditivo, em vez de permitir que cada ocorrência de crime recentemente observada seja realimentada no algoritmo, pode-se impor uma regra de amostragem tal que quanto maior a probabilidade de a polícia ser enviada para uma delegacia específica, menos prováveis serão os dados observados nessas atribuições. são incorporados ao algoritmo. Esses tipos de regras de amostragem ajudam a evitar que os modelos façam previsões que recaem desproporcionalmente em um grupo específico.
3 . Avaliando o desempenho em relação a métricas alternativas
Para algoritmos que tomam decisões de classificação entre diferentes grupos, também é importante considerar o desempenho do modelo em relação a outras métricas além da precisão – por exemplo, a taxa de falsos positivos ou a taxa de falsos negativos.
Por exemplo, consideremos um algoritmo de justiça criminal utilizado para atribuir pontuações de risco de reincidência aos arguidos. Alguém é rotulado como de “alto risco” se tiver ⅔ chance prevista de reincidência dentro de dois anos. Suponha que os dados de treinamento contenham apenas dois grupos: Grupo A e Grupo B; cada grupo tem um perfil subjacente diferente para a reincidência. Neste exemplo, possíveis métricas de modelo alternativas seriam:
- Taxa de falsos positivos: probabilidade de rotular alguém como de alto risco, mesmo que não tenha cometido reincidência.
- Taxa de falsos negativos: a probabilidade de rotular alguém como de baixo risco, mesmo que tenha reincidido.
Pode-se então aplicar restrições de modelo para fazer com que o algoritmo satisfaça alguma regra de justiça. As regras comuns incluem 1 :
Google Research (2016), Discriminação de ataques com aprendizado de máquina mais inteligente .
Gorbett-Davis e Goel (2018), A Medida e a Má Medida da Justiça .
- Paridade preditiva: deixe os algoritmos fazerem previsões sem considerar características como gênero e raça. No exemplo da reincidência, os réus brancos e negros seriam submetidos aos mesmos padrões de pontuação de risco.
- Bem calibrado: Em situações com mais de um resultado previsto (por exemplo, pontuações de risco em uma escala de um a nove em vez de simplesmente risco alto versus baixo risco), isso significaria que a proporção prevista de reincidência é a mesma entre os grupos para todos os possíveis valor da pontuação.
- Equilíbrio da taxa de erro: Exigir que certas medidas de desempenho sejam mantidas iguais entre os grupos. No exemplo da reincidência, o algoritmo seria necessário para atingir a mesma taxa de falsos positivos ou a mesma taxa de falsos negativos entre os grupos A e B.
No modelo simplificado de reincidência abaixo, a regra de paridade preditiva foi imposta de tal forma que, para ambos os grupos, 67% das pessoas rotuladas como de “alto risco” são de facto novamente presas. Brinque com o modelo definindo o número total de pessoas no Grupo A que são rotuladas como de “alto risco”. Você pode definir esse número de forma que o modelo atinja taxas iguais de falsos negativos, além da paridade preditiva? Existe um valor que permite ao modelo atingir taxas iguais de falsos positivos e falsos negativos e paridade preditiva?
| Baixo risco | Alto risco | Total | |
| Não reincide | 60 | 10 | 70 |
| Reincide | 10 | 20 | 30 |
| Total | 70 | 100 |
| Baixo risco | Alto risco | Total | |
| Não reincide | 20 | 20 | 40 |
| Reincide | 20 | 40 | 60 |
| Total | 40 | 60 | 100 |
| grupo A | Grupo B | |
| Precisão: | 67% | 67% |
| Taxa de falso positivo: | 14% | 50% |
| Taxa de falso negativo: | 33% | 33% |
4 . Indo além de dados e algoritmos
Além de combater o preconceito diretamente nos dados e/ou no algoritmo, existem medidas mais amplas que as empresas de tecnologia, em particular, começaram a adotar. Uma medida é estabelecer diretrizes éticas de IA, onde a minimização de preconceitos seja incluída como parte dos objetivos globais de IA de uma empresa. (Como o ML é um subconjunto da IA, as mesmas diretrizes éticas também se aplicariam ao desenvolvimento de produtos de ML.) O Google lista explicitamente “Evitar criar ou reforçar preconceitos injustos” como o segundo princípio para aplicações de IA. Da mesma forma, a Microsoft inclui “os sistemas de IA devem tratar todas as pessoas de forma justa” entre seus princípios de IA.
Outra medida é realizar auditorias de algoritmos de terceiros para garantir que cada produto de IA atenda às diretrizes de IA da empresa; um número crescente de empresas de consultoria e análise de dados está começando a oferecer esses serviços de auditoria . Uma medida ainda mais ampla que visa a fonte humana é promover a diversidade na força de trabalho de IA/ML. Em 2018, apenas 13% dos CEOs de IA eram mulheres e menos de 7% dos docentes de engenharia com estabilidade se identificavam como afro-americanos ou hispânicos . Black in AI e AI4ALL são exemplos emergentes de iniciativas para mudar o cenário atual, promovendo uma comunidade mais diversificada e inclusiva de profissionais de IA/ML.
Embora estas medidas por si só não eliminem completamente os preconceitos da aprendizagem automática, reflectem como as empresas e a comunidade mais ampla de IA/ML estão cada vez mais conscientes da necessidade de abordar os preconceitos à medida que tais tecnologias se tornam cada vez mais amplamente utilizadas.
Conclusão
Desafios para lidar com o preconceito no aprendizado de máquina
Embora a secção anterior tenha mencionado abordagens que podem ser adotadas para mitigar preconceitos no BC, eliminar verdadeiramente essas disparidades é um problema mais desafiante do que pode parecer à primeira vista. A recolha de dados que representem perfeitamente todos os subgrupos de uma população, embora certamente útil, não é uma panacéia. Se os sistemas subjacentes que estão sendo modelados forem eles próprios injustos (por exemplo, bairros minoritários tendem a ser desproporcionalmente policiados, famílias pobres e de minorias têm maior probabilidade de serem denunciadas a linhas diretas de abuso infantil, gerentes de contratação podem preferir homens a mulheres para funções de engenharia de software), então o os resultados do modelo ainda acabarão refletindo esses comportamentos tendenciosos. Por outro lado, a remoção do preconceito do BC, embora possa gerar resultados menos preocupantes do ponto de vista ético, também não resolverá as injustiças sociais subjacentes.
Outro desafio é identificar exatamente o que significa um resultado “justo”. Voltando ao exemplo da reincidência, será que o modelo é igualmente bom a prever que grupos de arguidos cometerão outro crime (paridade preditiva), mesmo que o modelo rotule incorretamente mais arguidos do Grupo B como propensos a reincidir? Ou o objetivo deveria ser que o modelo previsse incorretamente quais réus reincidirão em taxas iguais entre os dois grupos (taxas iguais de falsos positivos)? Ou que o modelo não consegue detectar reincidentes na mesma proporção entre os dois grupos (taxas iguais de falsos negativos)? Todas são formas válidas de definir “justiça”, mas foi provado que é matematicamente impossível satisfazer todas estas condições simultaneamente. Tentar ser justo de uma forma significa necessariamente ser injusto de outra forma.
Além disso, a optimização para estas definições pode impor outros custos sociais. Treinar um modelo para ser imparcial na previsão de quem irá reincidir pode levar a um aumento nas taxas de criminalidade violenta porque mais arguidos de alto risco são libertados. Assim, existem tensões entre equilibrar o bem-estar social (por exemplo, segurança pública) com a justiça algorítmica (por exemplo, minimizar a prisão desnecessária de indivíduos inofensivos).
Outro problema é que, por vezes, o que pode ser considerado tendencioso em algumas situações pode ser exactamente o resultado desejado noutros casos. Por exemplo, alguém que pretenda estudar a proporção de personagens masculinos versus femininos que aparecem em romances de língua inglesa ao longo das últimas centenas de anos iria querer que o seu algoritmo detectasse associações de género encontradas em profissões, a fim de identificar o sexo desse personagem. Esse “viés” é crítico para este tipo de análise, mas seria totalmente problemático se o modelo fosse concebido para selecionar currículos para ofertas de emprego.
O que pode ser feito para corrigir a situação?
Para que a situação não pareça desesperadora, existem medidas que as empresas e organizações podem tomar para melhorar os resultados dos seus esforços de modelação. Um desses passos é garantir que o grupo que trabalha nos problemas de BC seja diversificado em termos de compreensão de pessoas de diferentes ambientes socioeconómicos, para que sejam representados o maior número possível de pontos de vista. Além disso, os funcionários devem ser treinados na identificação dos seus próprios preconceitos, a fim de aumentar a sua consciência de como os seus próprios pressupostos e percepções do mundo influenciam o seu trabalho.
Outro ponto importante é ser transparente e aberto sobre o que exatamente um modelo de ML faz, como chegou aos resultados que alcançou e para quais métricas de precisão ele foi otimizado. Ser capaz de explicar por que o modelo previu, por exemplo, que alguém não era digno de crédito não só permite que esse indivíduo entenda o que aconteceu, mas também facilita a identificação de problemas no desempenho do modelo. Por último, reconhecer que o ML não é uma solução mágica que resolverá todos os problemas do mundo, mas que, como qualquer outra ferramenta, tem as suas limitações e fraquezas, ajudará a manter uma perspectiva mais realista sobre o que estes modelos podem (e não podem) alcançar. A Microsoft e o Google começaram recentemente a incluir avisos sobre os riscos do uso de IA em seus registros na Securities and Exchange Commission.
Algoritmos estão sendo usados para recomendar o que assistir em seguida na Netflix, filtrar spam das caixas de entrada e oferecer instruções que ajudam os motoristas a evitar o trânsito. Estão também a ser utilizados para determinar se a liberdade condicional deve ser concedida, quais os bairros que devem ser policiados de forma mais rigorosa, se as crianças estão a ser vítimas de abuso e quem deve ser contratado. Os riscos são reais quando se trata de como as decisões tomadas pelos modelos de ML e IA estão impactando a vida das pessoas e, se as tendências continuarem, esses algoritmos serão cada vez mais utilizados para ajudar a tomar essas decisões.
O preconceito na aprendizagem automática impõe custos graves tanto aos indivíduos como à sociedade como um todo, ao negar injustamente oportunidades às pessoas e ao mesmo tempo perpetuar estereótipos e desigualdades. Combater o preconceito é um problema desafiador para o qual não existem soluções simples ou respostas claras. Mas é imperativo que os profissionais de ML o façam utilizando dados mais representativos, avaliando os resultados em relação a várias definições diferentes de precisão e estando mais conscientes dos seus próprios preconceitos. O ML e a IA irão de fato mudar o mundo; vamos garantir que eles mudem o mundo para melhor.


