Os modelos de difusão de texto para imagem têm demonstrado capacidades excepcionais na geração de imagens de alta qualidade a partir de mensagens de texto. No entanto, os principais modelos apresentam bilhões de parâmetros e, consequentemente, são caros para executar, exigindo desktops ou servidores poderosos (por exemplo, Difusão estável, DALL-E e Imagen). Embora avanços recentes em soluções de inferência em Android via Media Pipe e iOS via Core ML tenham sido feitos no ano passado, a geração rápida (sub-segundo) de texto para imagem em dispositivos móveis permaneceu fora de alcance.
Para esse fim, em “MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices“, apresentamos uma nova abordagem com potencial para a rápida geração de texto para imagem no dispositivo. O Mobile Diffusion é um modelo eficiente de difusão latente projetado especificamente para dispositivos móveis. Também adotamos o DiffusionGAN para obter uma amostragem em uma etapa durante a inferência, que ajusta um modelo de difusão pré-treinado enquanto aproveita um GAN para modelar a etapa de redução de ruído. Testámos o Mobile Diffusion em dispositivos iOS e Android premium, e pode ser executado em meio segundo para gerar uma imagem de alta qualidade de 512×512. O seu tamanho de modelo comparativamente pequeno, de apenas 520M parâmetros, rna-o especialmente adequado para a implantação móvel.
Contexto
A relativa ineficiência dos modelos de difusão de texto para imagem decorre de dois desafios principais. Em primeiro lugar, a concepção inerente dos modelos de difusão requer denoising interativo para gerar imagens, necessitando de múltiplas avaliações do modelo. Em segundo lugar, a complexidade da arquitetura da rede nos modelos de difusão de texto para imagem envolve um número substancial de parâmetros, que atingem regularmente os milhares de milhões e resultam em avaliações computacionalmente dispendiosas. Consequentemente, apesar dos potenciais benefícios da utilização de modelos generativos em dispositivos móveis, tais como a melhoria da experiência do utilizador e a resolução de problemas de privacidade emergentes, a literatura atual continua relativamente inexplorada.
A otimização da eficiência da inferência em modelos de difusão de texto para imagem tem sido uma área de investigação ativa. Estudos anteriores concentram-se predominantemente na abordagem do primeiro desafio, procurando reduzir o número de avaliações de funções (NFEs). Aproveitando solucionadores numéricos avançados (por exemplo, DPM) ou técnicas de destilação (por exemplo, destilação progressiva, destilação por consistência), o número de etapas de amostragem necessárias foi significativamente reduzido de várias centenas para um único dígito. Algumas técnicas recentes, como DiffusionGAN e Adversarial Diffusion Distillation, reduzem mesmo a um único passo necessário.
No entanto, em dispositivos móveis, mesmo um pequeno número de etapas de avaliação pode ser lento devido à complexidade da arquitetura do modelo. Até agora, a eficiência arquitetónica dos modelos de difusão texto-imagem tem recebido comparativamente menos atenção. Um punhado de trabalhos anteriores aborda brevemente esse assunto, envolvendo a remoção de blocos de rede neural redundantes (por exemplo, SnapFusion). No entanto, esses esforços carecem de uma análise abrangente de cada componente dentro da arquitetura do modelo, ficando assim aquém de fornecer um guia holístico para projetar arquiteturas altamente eficientes.
Difusão móvel
Para superar eficazmente os desafios impostos pelo poder computacional limitado dos dispositivos móveis, é necessário explorar em profundidade e de forma holística a eficiência arquitetónica do modelo. Na prossecução deste objetivo, a nossa investigação leva a cabo um exame detalhado de cada constituinte e operação computacional dentro da arquitetura da UNet da Stable Diffusion. Apresentamos um guia completo para a criação de modelos de difusão de texto para imagem altamente eficientes, culminando no MobileDiffusion.
O design do MobileDiffusion segue o dos modelos de difusão latente. Ele contém três componentes: um codificador de texto, uma UNet de difusão e um decodificador de imagem. Para o codificador de texto, usamos o CLIP-ViT/L14, que é um modelo pequeno (125M parâmetros) adequado para dispositivos móveis. De seguida, concentramo-nos na UNet de difusão e no decodificador de imagem.
UNet de difusão
Como ilustrado na figura abaixo, os UNets de difusão intercalam normalmente blocos de transformação e blocos de convolução. Realizamos uma investigação exaustiva destes dois blocos de construção fundamentais. Ao longo do estudo, controlamos o pipeline de formação (por exemplo, dados, optimizador) para estudar os efeitos de diferentes arquitecturas.
Nos modelos clássicos de difusão texto-imagem, um bloco transformador consiste numa camada de autoatenção (SA) para modelar as dependências de longo alcance entre as características visuais, uma camada de atenção cruzada (CA) para captar as interações entre o condicionamento do texto e as características visuais, e uma camada de feed-forward (FF) para pós-processar o resultado das camadas de atenção. Estes blocos transformadores desempenham um papel fundamental nos modelos de difusão texto-imagem, servindo como componentes primários responsáveis pela compreensão do texto. No entanto, eles também representam um desafio significativo de eficiência, dado o gasto computacional da operação de atenção, que é quadrático para o comprimento da sequência. Seguimos a ideia da arquitetura UViT, que coloca mais blocos de transformadores no ponto de estrangulamento da UNet. Esta escolha de design é motivada pelo facto de o cálculo da atenção consumir menos recursos no gargalo devido à sua menor dimensão.
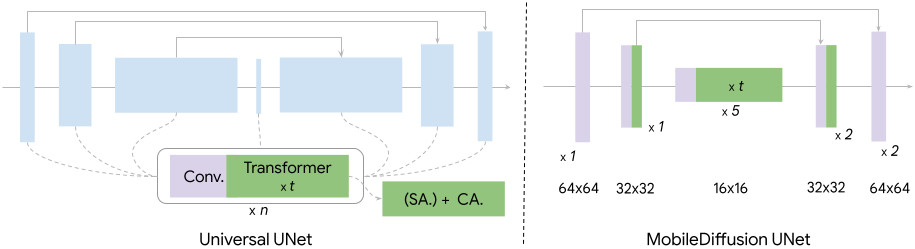
Os blocos de convolução, em particular os blocos ResNet, são implantados em cada nível da UNet. Embora estes blocos sejam fundamentais para a extração de características e o fluxo de informação, os custos computacionais associados, especialmente a níveis de alta resolução, podem ser substanciais. Uma abordagem comprovada neste contexto é a convolução separável. Observámos que a substituição de camadas de convolução regulares por camadas de convolução separáveis leves nos segmentos mais profundos da UNet produz um desempenho semelhante.
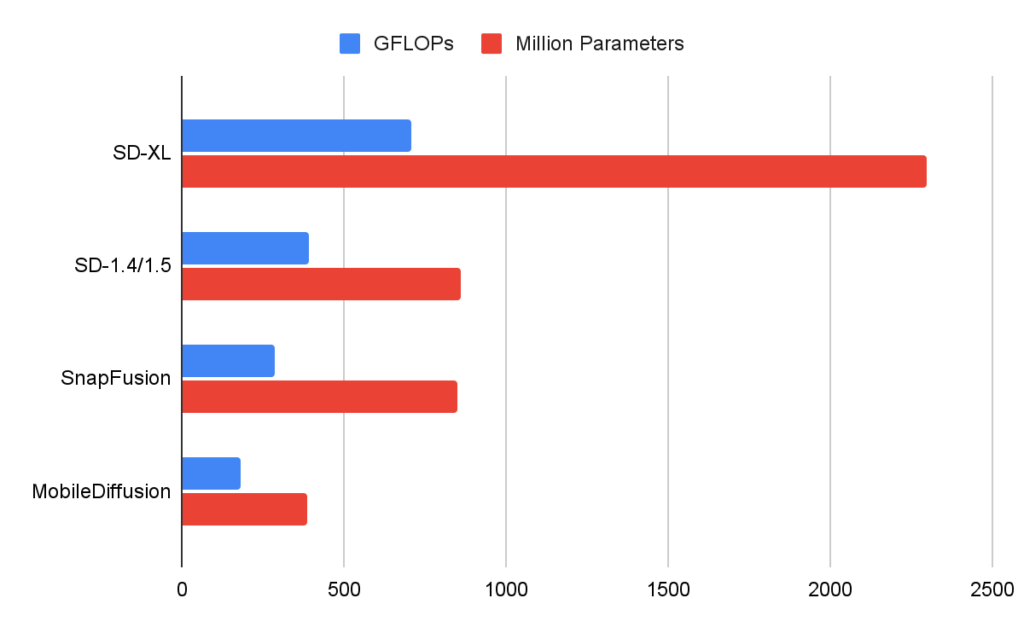
Na figura abaixo, comparamos as UNets de vários modelos de difusão. O nosso MobileDiffusion apresenta uma eficiência superior em termos de FLOPs (operações de vírgula flutuante) e número de parâmetros.
Decodificador de imagem
Além da UNet, também otimizamos o decodificador de imagem. Treinamos um autoencoder variacional (VAE) para codificar uma imagem RGB para uma variável latente de 8 canais, com tamanho espacial 8× menor da imagem. Uma variável latente pode ser descodificada para uma imagem e fica 8 vezes maior em tamanho. Para aumentar ainda mais a eficiência, concebemos uma arquitetura de descodificador leve, reduzindo a largura e a profundidade do original. O decodificador leve resultante leva a um aumento significativo no desempenho, com quase 50% de melhoria na latência e melhor qualidade. Para mais pormenores, consulte o nosso paper.

| Descodificado | #Paramas (M) | PSNR↑ | SSIM↑ | LPIPS↓ |
| DP | 49.5 | 26.7 | 0.76 | 0.037 |
| Nossos | 39.3 | 30.0 | 0.83 | 0.032 |
| Nossos-Lite | 9.8 | 30.2 | 0.84 | 0.032 |
| Avaliação da qualidade dos descodificadores VAE. O nosso descodificador lite é muito mais pequeno do que o SD, com melhores métricas de qualidade, incluindo relação sinal-ruído de pico (PSNR), medida de índice de similaridade estrutural (SSIM) e similaridade percentual aprendida de imagens (LPIPS). |
Amostragem em uma etapa
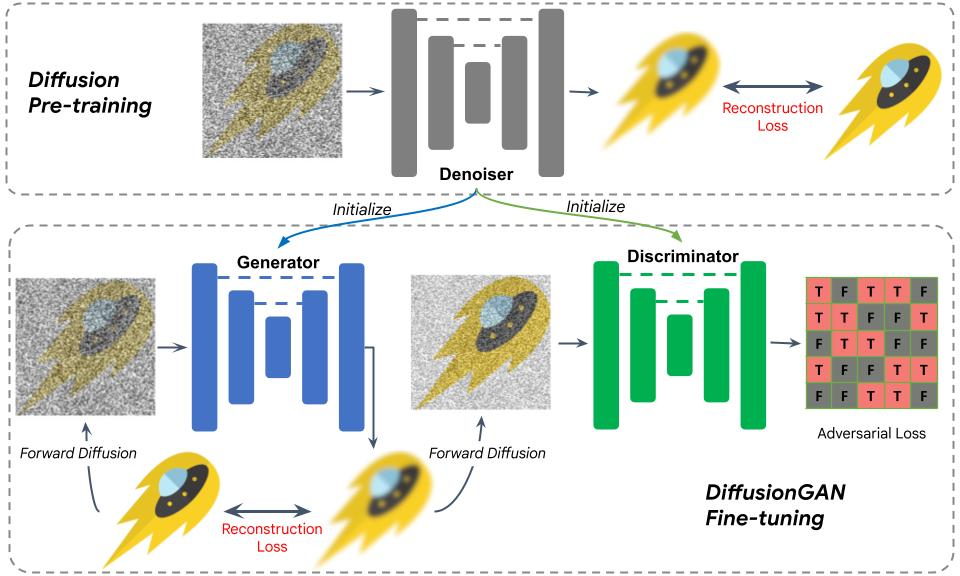
Para além de otimizar a arquitetura do modelo, adoptamos um DiffusionGAN híbrido para conseguir uma amostragem num só passo. O treinamento de modelos híbridos DiffusionGAN para geração de texto para imagem encontra várias complexidades. Nomeadamente, o discriminador, um classificador que distingue os dados reais dos dados gerados, tem de fazer julgamentos com base na textura e na semântica. Além disso, o custo de formação de modelos de texto-imagem pode ser extremamente elevado, particularmente no caso de modelos baseados em GAN, em que o discriminador introduz parâmetros adicionais. Modelos de texto-imagem puramente baseados em GAN (por exemplo, StyleGAN-T, GigaGAN) enfrentam complexidades semelhantes, resultando em um treinamento altamente complexo e caro.
Para superar esses desafios, usamos uma UNet de difusão pré-treinada para inicializar o gerador e o discriminador. Este design permite uma inicialização perfeita com o modelo de difusão pré-treinado. Postulamos que as características internas do modelo de difusão contêm informações ricas sobre a intrincada interação entre dados textuais e visuais. Esta estratégia de inicialização simplifica significativamente o treino.
A figura abaixo ilustra o procedimento de formação. Após a inicialização, uma imagem com ruído é enviada para o gerador para difusão num passo. O resultado é avaliado em relação à verdade terrestre com uma perda de reconstrução, semelhante ao treinamento do modelo de difusão. Em seguida, adicionamos ruído à saída e enviamo-lo para o discriminador, cujo resultado é avaliado com uma perda de GAN, adoptando efectivamente o GAN para modelar um passo de redução de ruído. Ao usar pesos pré-treinados para inicializar o gerador e o discriminador, o treinamento se torna um processo de ajuste fino, que converge em menos de 10 mil iterações.
Resultados
Abaixo mostramos exemplos de imagens geradas pelo nosso MobileDiffusion com amostragem num passo do DiffusionGAN. Com um modelo tão compacto (520M parâmetros no total), o MobileDiffusion pode gerar imagens diversas de alta qualidade para vários domínios.

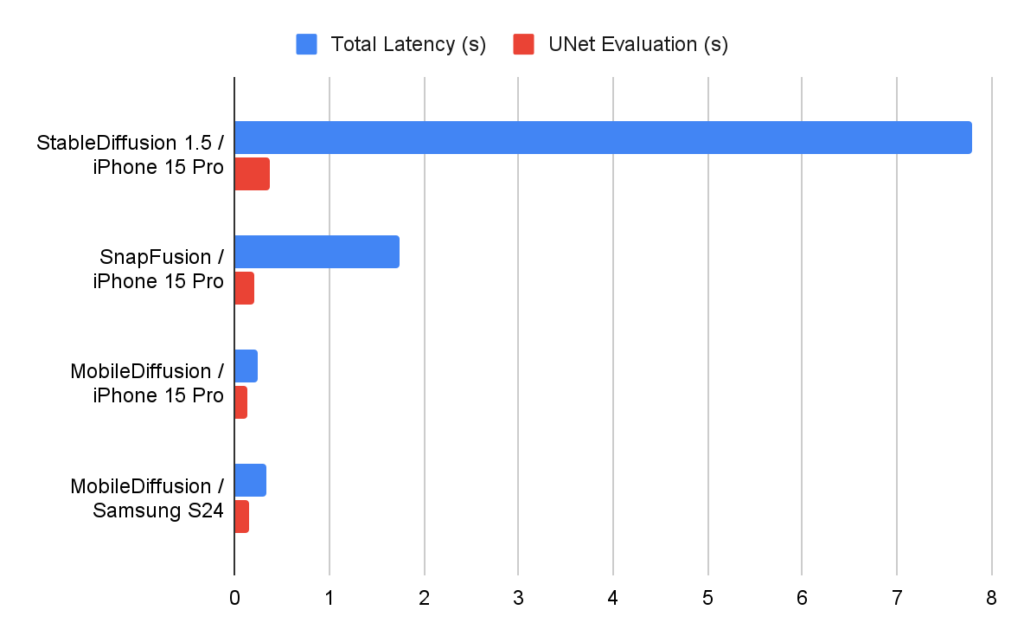
Medimos o desempenho do nosso MobileDiffusion em dispositivos iOS e Android, utilizando diferentes otimizadores de tempo de execução. Os números da latência são apresentados abaixo. Vemos que o MobileDiffusion é muito eficiente e pode ser executado em meio segundo para gerar uma imagem de 512×512. Esta velocidade relâmpago permite potencialmente muitos casos de utilização interessantes em dispositivos móveis.
Conclusão
Com eficiência superior em termos de latência e tamanho, o MobileDiffusion tem o potencial de ser uma opção muito amigável para implantações móveis, dada sua capacidade de permitir uma experiência rápida de geração de imagem ao digitar prompts de texto. E garantimos que qualquer aplicação desta tecnologia estará em linha com as práticas de IA responsáveis da Google.
Agradecimentos
Gostaríamos de agradecer aos nossos colaboradores e contribuintes que ajudaram a trazer o MobileDiffusion para o dispositivo: Zhisheng Xiao, Yanwu Xu, Jiuqiang Tang, Haolin Jia, Lutz Justen, Daniel Fenner, Ronald Wotzlaw, Jianing Wei, Raman Sarokin, Juhyun Lee, Andrei Kulik, Chuo-Ling Chang e Matthias Grundmann.
Publicado por Yang Zhao, Engenheiro de Software Sénior, e Tingbo Hou, Engenheiro de Software Sênior, Core ML