Os modelos de aprendizagem automática no mundo real são frequentemente treinados com base em dados limitados que podem conter vieses estatísticos não intencionais. Por exemplo, no conjunto de dados de imagens de celebridades do CELEBA, um número desproporcionado de celebridades femininas tem cabelo loiro, levando a que os classificadores prevejam incorretamente “louro” como a cor do cabelo para a maioria dos rostos femininos – aqui, o género é uma caraterística espúria para prever a cor do cabelo. Estas tendências injustas podem ter consequências significativas em aplicações críticas como o diagnóstico médico.
Surpreendentemente, trabalhos recentes também descobriram uma tendência inerente das redes profundas de amplificar esses vieses estatísticos, através do chamado viesamento de simplicidade do aprendizado profundo. Esse viés é a tendência das redes profundas de identificar características fracamente preditivas no início do treinamento e continuar a ancorar nessas características, deixando de identificar características mais complexas e potencialmente mais precisas.
Com o exposto acima em mente, propomos correções simples e eficazes para esse duplo desafio de recursos espúrios e viés de simplicidade, aplicando leituras antecipadas e esquecimento de recursos. Primeiro, em “Usando leituras antecipadas para mediar o viés featural na destilação”, mostramos que fazer previsões das camadas iniciais de uma rede profunda (referidas como “leituras antecipadas”) pode sinalizar automaticamente problemas com a qualidade das representações aprendidas. Em particular, estas previsões são mais frequentemente erradas, e mais confiantes, quando a rede se baseia em características espúrias. Usamos essa confiança errônea para melhorar os resultados na destilação de modelos, uma configuração em que um modelo maior de “professor” orienta o treinamento de um modelo menor de “aluno”. Depois, em “Overcoming Simplicity Bias in Deep Networks using a Feature Sieve“, intervimos diretamente nestes sinais indicadores fazendo com que a rede “esqueça” as características problemáticas e, consequentemente, procure características melhores e mais preditivas. Isto melhora substancialmente a capacidade do modelo de generalizar para domínios não vistos em comparação com abordagens anteriores. Os nossos Princípios de IA e as nossas Práticas de IA responsáveis orientam a forma como investigamos e desenvolvemos estas aplicações avançadas e ajudam-nos a enfrentar os desafios colocados pelos enviesamentos estatísticos.
Leituras precoces para destilação de desbaste
Primeiro, ilustramos o valor de diagnóstico de leituras iniciais e sua aplicação na destilação sem enviesamento, ou seja, garantindo que o modelo do aluno herde a resiliência do modelo do professor ao viés de recurso por meio da destilação. Começamos com uma estrutura de destilação padrão em que o aluno é treinado com uma mistura de correspondência de rótulos (minimizando a perda de entropia cruzada entre as saídas do aluno e os rótulos da verdade básica) e correspondência do professor (minimizando a Divergência KL perda entre as saídas do aluno e do professor para qualquer entrada dada).
Suponha que se treine um decodificador linear, ou seja, uma pequena rede neural auxiliar denominada Aux, em cima de uma representação intermediária do modelo do aluno. Referimo-nos à saída deste descodificador linear como uma leitura antecipada da representação da rede. A nossa conclusão é que as leituras iniciais cometem mais erros em instâncias que contêm características espúrias e, além disso, a confiança nesses erros é mais elevada do que a confiança associada a outros erros. Isto sugere que a confiança nos erros das primeiras leituras é um indicador bastante forte e automatizado da dependência do modelo em relação a características potencialmente espúrias.
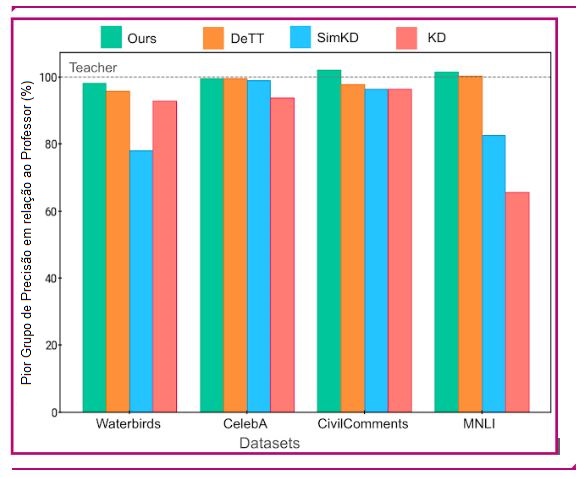
Utilizámos este sinal para modular a contribuição do professor na perda de destilação por instância e, como resultado, encontrámos melhorias significativas no modelo de aluno treinado.
Avaliamos a nossa abordagem em conjuntos de dados de referência padrão conhecidos por conterem correlações espúrias (Waterbirds, CelebA, CivilComments, MNLI). Cada um destes conjuntos de dados contém agrupamentos de dados que partilham um atributo potencialmente relacionado com o rótulo de uma forma espúria. Por exemplo, o conjunto de dados CelebA acima mencionado inclui grupos como {homem louro, mulher loura, homem não loiro, mulher não loura}, com os modelos a terem normalmente o pior desempenho no grupo {mulher não loura} ao preverem a cor do cabelo. Assim, uma medida do desempenho do modelo é sua pior precisão de grupo, ou seja, a menor precisão entre todos os grupos conhecidos presentes no conjunto de dados. Melhoramos a pior precisão de grupo dos modelos de alunos em todos os conjuntos de dados; além disso, também melhoramos a precisão geral em três dos quatro conjuntos de dados, mostrando que nossa melhoria em qualquer grupo não vem à custa da precisão em outros grupos. Mais detalhes estão disponíveis em nosso paper.
Ultrapassar o enviesamento da simplicidade com um crivo de características
Num segundo projeto, estreitamente relacionado, intervimos diretamente na informação fornecida pelas primeiras leituras, para melhorar a aprendizagem de características e a generalização. O fluxo de trabalho alterna entre identificar características problemáticas e apagar características identificadas da rede. Nossa hipótese principal é que as características iniciais são mais propensas ao viés de simplicidade e que, ao apagar (“peneirar”) essas características, permitimos características mais ricas representações para o leitor.

- Descrevemos as etapas de identificação e eliminação em detalhe:
– Identificação de características simples: Treinamos o modelo primário e o modelo de leitura (AUX acima) de forma convencional, através de propagação para a frente e para trás. Note-se que o feedback da camada auxiliar não é retro propagado para a rede principal. Isto é para forçar a camada auxiliar a aprender com as características já disponíveis em vez de as criar ou reforçar na rede principal.
– Aplicando a peneira de características: Nosso objetivo é apagar as características identificadas nas camadas iniciais da rede neural com o uso de uma nova perda de esquecimento, Lf , que é simplesmente a entropia cruzada entre a leitura e uma distribuição uniforme sobre os rótulos. Essencialmente, todas as informações que levam a leituras não triviais são apagadas da rede primária. Nesta etapa, a rede auxiliar e as camadas superiores da rede principal são mantidas inalteradas.
Podemos controlar especificamente a forma como o filtro de características é aplicado a um determinado conjunto de dados através de um pequeno número de parâmetros de configuração. Ao alterar a posição e a complexidade da rede auxiliar, controlamos a complexidade das características identificadas e apagadas. Ao modificar a mistura das etapas de aprendizagem e esquecimento, controlamos o grau em que o modelo é desafiado a aprender características mais complexas. Essas escolhas, que são dependentes do conjunto de dados, são feitas por meio de pesquisa hiper paramétrica para maximizar a precisão da validação, uma medida padrão de generalização. Como incluímos o “não esquecimento” (ou seja, o modelo de linha de base) no espaço de pesquisa, esperamos encontrar configurações que sejam pelo menos tão boas quanto a linha de base.
Abaixo, mostramos os recursos aprendidos pelo modelo de linha de base (linha do meio) e nosso modelo (linha inferior) em dois conjuntos de dados de referência – reconhecimento de atividade tendenciosa (BAR) e categorização de animais (NICO). A importância dos recursos foi estimada usando a pontuação de importância baseada em gradiente post-hoc (GRAD-CAM), com a extremidade laranja-vermelha do espectro indicando alta importância, enquanto o verde-azul indica baixa importância. Como se pode ver abaixo, os nossos modelos treinados concentram-se no objeto principal de interesse, enquanto o modelo de base tende a concentrar-se no objeto principal de interesse.

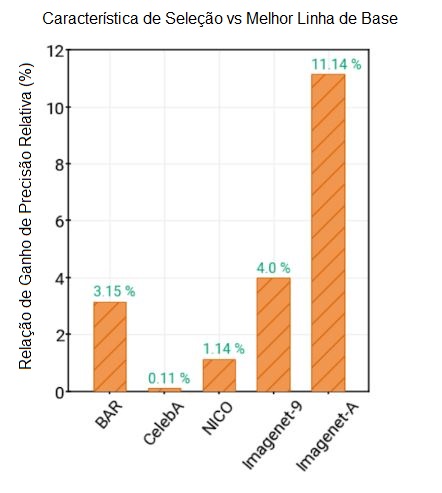
Por meio dessa capacidade de aprender características melhores e generalizáveis, mostramos ganhos substanciais em relação a uma série de linhas de base relevantes em conjuntos de dados de referência de características espúrias do mundo real: BAR, CelebA Hair, NICO e ImagenetA, com margens de até 11% (veja a figura abaixo). Mais pormenores stão disponíveis no nosso documento.
Conclusão
Esperamos que o nosso trabalho sobre leituras antecipadas e a sua utilização na seleção de características para generalização estimule o desenvolvimento de uma nova classe de abordagens de aprendizagem de características adversárias e ajude a melhorar a capacidade de generalização e a robustez dos sistemas de aprendizagem profunda.
Agradecimentos
O trabalho sobre a aplicação de leituras antecipadas à destilação de debiasing foi realizado em colaboração com os nossos parceiros académicos Durga Sivasubramanian, Anmol Reddy e o Prof. Ganesh Ramakrishnan no IIT Bombay. Estendemos a nossa sincera gratidão a Praneeth Netrapalli e Anshul Nasery pelos seus comentários e recomendações. Estamos também gratos a Nishant Jain, Shreyas Havaldar, Rachit Bansal, Kartikeya Badola, Amandeep Kaur e a todo o grupo de investigadores de pré-doutoramento do Google Research India por participarem nas discussões de investigação. Agradecimentos especiais a Tom Small pela criação da animação utilizada neste post.
Publicado por Rishabh Tiwari, investigador de pré-doutoramento, e Pradeep Shenoy, cientista investigador, Google Research

